
Introdução
O compilador é uma ferramenta fantástica, uma área de estudo em Ciências da Computação desafiadora e muito interessante.
O objetivo desse ebook é dar uma visão geral sobre o processo de compilação, abordando de forma teórica, na primeira parte, todas as etapas envolvidas na compilação de um programa. Na segunda parte, o objetivo é demonstrar de forma prática como podemos construir um compilador entendendo como alguns processos funcionam.
Não é objetivo ensinar todas as técnicas e algoritmos envolvidos na construção de um compilador, pois por si só o projeto isso é algo complexo e infinito.
Eu realmente acho sensacional essa ferramenta chamada Compilador e quero compartilhar com você, o conhecimento que tenho adquirido nesses últimos tempos estudando tudo isso. Espero que você tenha uma leitura entusiasmante e agradável, e lembre-se, eu estou à disposição para feedbacks e sugestões de melhorias nesse conteúdo.
Então, pegue um café e se divirta lendo Compiladores para Humanos.
Johni Douglas Marangon
Introdução
A construção de compiladores é um estudo sobre técnicas de tradução e aperfeiçoamento de programas, quase todo o software utilizado é traduzido de alguma forma por um compilador. Os compiladores são projetados de maneira cuidadosa e envolvem processos grandes e complexos que incluem milhares de linhas de código organizados em componentes que interagem de maneira a gerar uma compilação eficiente e rápida.
Os avanços na criação e melhoria das linguagens de programação impôs vários desafios aos projetistas de compiladores que precisam criar algoritmos para traduzir tudo isso em linguagem de máquina. Outro grande desafio é a evolução na arquitetura dos computadores, o que exige um constante aperfeiçoamento do compilador.
A tradução para a linguagem-objeto deve tirar o máximo proveito sobre o hardware e o software. É importante destacar que o desempenho de um sistema de computação é extremamente dependente da tecnologia de compilação utilizada.
Introdução e visão geral sobre compiladores
A construção de compiladores abrange diversas áreas de estudo em Ciências da Computação, como por exemplo conceitos de Linguagens de Programação, Arquitetura de Máquina, Algoritmos e Engenharia de Software. Nesse capítulo será apresentado uma introdução ao processo de compilação mostrando uma visão de alto nível da estrutura de um compilador.
As linguagens de programação e a arquitetura de computadores evoluem e estão cada vez mais sofisticados. O desafio dos projetistas de compiladores é criar algoritmos mais eficientes que visem obter um melhor desempenho no uso de memória e processamento.
Conhecer como um compilador funciona é essencial para entender a ligação entre Engenharia de Software, Linguagens de Programação, Sistemas Operacionais e Arquitetura de Computadores.
Nessa primeira parte do ebook vamos apresentar as etapas envolvidas no processo de compilação e como estas se inter-relacionam para gerar um programa executável.
O Compilador
O compilador é um software complexo que converte uma linguagem fonte, ou linguagem origem, em uma linguagem destino, ou linguagem-objeto, ou seja, converte um programa originado de uma linguagem de programação para uma linguagem que possa ser entendida e executada por um computador. Durante a compilação são executadas tarefas que fazem a tradução de uma linguagem em outra.
Existem dois princípios fundamentais na construção de compiladores:
-
O compilador deve preservar o significado do programa a ser compilado; e
-
O compilador deve melhorar o programa de entrada de alguma forma perceptível.
As etapas de compilação são complexas e exigiam um esforço significativo, sendo que os primeiros compiladores eram escritos em código binário e salvos na memória ROM. Hoje nós temos um conjunto de ferramentas que facilitam a criação e manutenção de compiladores, muitas dessas ferramentas são escritas em linguagem como Java, C e C++ e já automatizam boa parte da construção de um compilador.
Essas ferramentas geram códigos que podem ser incluídos no projeto do compilador. Um exemplo são os geradores de analisadores léxicos, que com base em expressões regulares geram um algoritmo capaz de identificar os elementos léxicos de uma linguagem de programação.
O compilador precisa traduzir um conjunto infinito de programas escritos em uma linguagem de programação e o resultado desse processo deve ser um código eficiente que deve ser executado em diversas arquiteturas de processadores.
Um conceito muito importante no estudo de compiladores é a otimização, que se refere as atentivas de produzir um compilador que gere um código mais eficiente. Essa é uma etapa cada vez mais importante e complexa devido à grande variedade de arquiteturas de processadores. O tempo de compilação é outro fator muito importante que deve ser levado em consideração durante o desenvolvimento de um compilador.
Linguagens de programação
Podemos definir uma linguagem comumente chamada de língua ou idioma como um meio de comunicação entre pessoas. Em programação definimos a linguagem como o meio de comunicação entre o pensamento humano e as ações de um computador.
Todo o software executado em um computador foi escrito em alguma linguagem e antes que ele possa executar instruções diretamente no processador, outro programa deve ser utilizado para traduzir essa linguagem em um formato que possa ser entendido e executado pelo computador, esse programa é chamado de compilador.
As linguagens de programação são projetadas para permitir que seres humanos expressem processos computacionais em uma sequência de operações, tal como ler um arquivo e imprimir o seu conteúdo em algum dispositivo como, por exemplo, uma impressora.
Os programas executados no computador são sequências de 0 e 1 que representam valores inteiros, ponto flutuante, strings, etc., ou ainda instruções que indicam o que o computador deve fazer. A memória do computador é dividida em partes que possuem endereços únicos, todo o programa armazenado na memória é executado pela CPU que possui registradores que guardam dados temporários utilizados em operações.
Pense na seguinte situação: para somar o número armazenado no endereço de memória $000011 com o número armazenado no endereço de memória $000012 é necessário:
- copiar o conteúdo da memória
$000011para um registrador A; - copiar o conteúdo da memória
$000012para um registrado B; - somar o conteúdo de A e B e copiar o resultado para o endereço de memória
$000013.
Esse processo certamente é muito mais complexo do que simplesmente executar o comando c = a + b em uma determinada linguagem de programação.
Uma linguagem de programação é considera de alto nível quando sua representação está próxima do domínio da aplicação e do problema a ser resolvido. Os computadores por sua vez possuem sua própria linguagem denominada de baixo nível ou linguagem de máquina.
O processo de tradução de uma linguagem de alto nível para linguagem de baixo nível é feito via softwares conhecidos como compiladores e tem como entrada uma linguagem fonte, alto nível, e como saída uma linguagem-objeto, baixo nível.
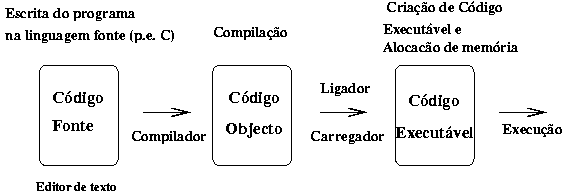
Na imagem acima podemos ver um diagrama que representa o processo de compilação, onde a entrada é um programa fonte e a saída é um programa objeto. Posteriormente, outros processos estão envolvidos na compilação como, por exemplo, o Ligador e o Carregador que criam o programa executável e auxiliam a sua execução.
As linguagens de programação podem ser classificadas em 5 gerações:
- Linguagens de máquina – baixo nível.
- Linguagens simbólicas ou montagem (Assembly) – baixo nível.
- Orientadas a usuário – alto nível.
- Orientadas a aplicação – alto nível.
- Linguagens de conhecimento – alto nível.
Nos primórdios da computação os computadores eram programados em linguagem de máquina, 1ª geração, utilizando notação binária, dessa forma os algoritmos eram complexos e de difícil implementação. A 2ª geração denominada de linguagens simbólicas ou de montagem, foi utilizada para minimizar a complexidade da 1ª geração e utilizavam mnêmicos que substituíam as instruções binárias. As instruções eram convertidas em código de máquina antes de serem executados, esse processo é conhecido como montagem. As linguagens de 3ª geração são voltadas para a solução de problemas específicos, por exemplo, o uso em aplicações comerciais e cientificas e esse momento surgem linguagens como COBOL, Pascal, Ada, FORTRAN, etc. Essas linguagens são classificas como procedimentais, declarativas, imperativas, lógicas, orientadas a objetos, etc. e os programas descrevem como os problemas serão resolvidos mediante instruções denominadas: entrada/saída; cálculos aritméticos; cálculos lógicos e controle de fluxo. Linguagens de 4ª geração formam projetadas para serem utilizadas por usuários finais, sendo de fácil utilização permitindo que os próprios usuários possam resolver os seus problemas (ex.: Excel, Access, SQL, etc.). Linguagens de 5ª geração são utilizadas em programas de inteligência artificial simulando comportamentos inteligentes, como PROLOG.
Cada vez mais os compiladores e as linguagens de programação assumem tarefas que antes eram de responsabilidade do programador, tais como: gerenciamento de memória, verificação de tipos e execução paralela.
Através das linguagens de programação, consegue-se:
- Facilidades para se escrever programas;
- Diminuição do problema de diferenças entre máquina;
- Facilidade de depuração e manutenção de programas;
- Melhoria da interface homem/máquina;
- Redução no custo e tempo necessário para o desenvolvimento de programas;
Os primeiros passos para tornar a linguagem mais inteligível por humanos ocorreu na década de 50 com o desenvolvimento de linguagens simbólicas ou assembly. As instruções em Assembly representavam mnemônicos das instruções de máquina, mais tarde surgiram ferramentas conhecidas como macro assemblers que permitiam abreviaturas parametrizadas de uma sequência de instruções Assembly.
O surgimento das linguagens de programação como o Fortran e Cobol influenciaram o desenvolvimento de compiladores, pois permitiam que construções de alto nível fossem possíveis de serem escritas de forma mais fácil. Posteriormente, com o surgimento de novas linguagem de programação com recursos cada vez mais inovadores, os compiladores se tornaram ferramentas muito mais sofisticadas.
Os programadores que utilizam linguagem de baixo nível têm mais controle sobre a execução de seus programas e podem produzir um código mais eficiente, mas esses programas são difíceis de serem escritos e executados em outras máquinas.
Com a evolução dos compiladores os programas escritos em linguagens de alto nível puderam ser otimizados para que fossem tão eficientes quanto programas escritos em linguagens de baixo nível. Linguagens de alto nível possuem recursos como laços, tipos de dados, controle de fluxo, etc. que facilitam a escrita de programas. Esses recursos são traduzidos para linguagens de baixo nível e executadas diretamente nos processadores através de instruções de máquina.
A criação de uma linguagem de programação depende do domínio da aplicação a que ela se propõe e isso também é um motivador para o surgimento de novas linguagens. Embora muitas tenham surgido com propósitos específicos, é comum uma linguagem ter muitas características e ser empregada em vários domínios de aplicação.
Veja no quadro abaixo alguns exemplos de domínios de aplicação e suas necessidades.
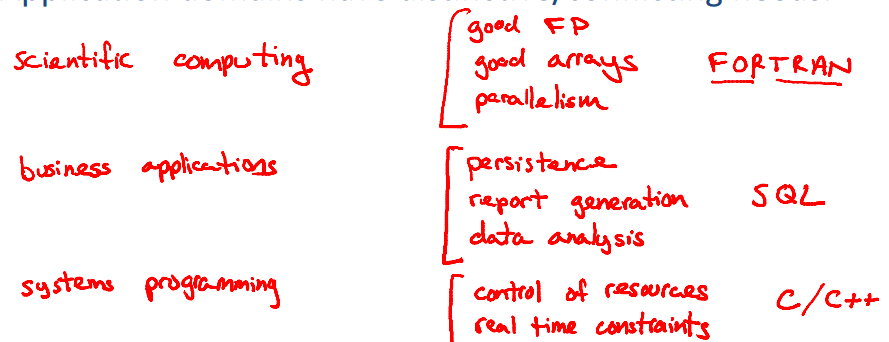
Muitas vezes temos que tomar a decisão de utilizar uma determinada linguagem de programação em um projeto, embora possa parecer fácil aprender uma nova linguagem, obter um nível considerável de expertise não é trivial. Não existe uma linguagem melhor ou pior e não é confortável fazer comparações diretas, o processo de escolha de uma linguagem deve analisar os recursos que cada uma oferece como solução aos problemas que o domínio da aplicação possui.
Quando geramos um compilador para uma linguagem de programação nós já temos uma linguagem que pode ser utilizada e manutenida, vamos supor que criamos uma linguagem chamada Legal, essa linguagem foi concebida com base em uma já existente, Python por exemplo - uma característica muito comum no surgimento de uma nova linguagem é ela ser proposta com base em outras - é importante ressaltar que, quando a linguagem Legal já estiver completa e com ela pudermos gerar seu próprio compilador, nós teremos um ciclo autossuficiente.
Tradutores
Os tradutores são sistemas que aceitam como entrada um programa escrito em uma linguagem e produzem como resultado um programa equivalente na mesma linguagem ou em linguagens diferentes. Os tradutores podem ser classificados em:
- Montadores: também chamados de assemblers, eles mapeiam instruções em linguagem simbólica para instruções em linguagem de máquina. Disassemblers ou desmontadores fazem o processo inverso.
- Macro assemblers: funcionam da mesma forma que os montadores, porém podem ser criados “macros” que representam uma sequência de comandos em linguagem simbólica.
- Compiladores: mapeiam programas escritos em linguagem de alto nível para linguagem simbólica ou de máquina.
- Pré-compiladores: também chamados de pré-processadores ou filtros, são programas que estendem a sintaxe de uma linguagem de alto nível com o objetivo de fazer a conversão entre duas linguagens de alto nível.
- Interpretadores: Possuem como entrada uma linguagem intermediária ou a própria linguagem fonte, e um programa compilado produz o efeito de execução.
Compiladores vs. Interpretadores
Diferente do compilador o interpretador recebe como estrada uma especificação executável e produz como saída, a execução dessa especificação. Linguagens como PHP, Scheme, Python são interpretadas.
Um interpretador pode ser entendido como um processo que, ao invés de visar um conjunto de instruções de um processador, visa produzir o efeito de sua execução. Eles normalmente interpretam uma representação intermediária do programa fonte.
No esquema abaixo podemos ter uma ideia macro das diferenças de funcionamento de um compilador e um interpretador.
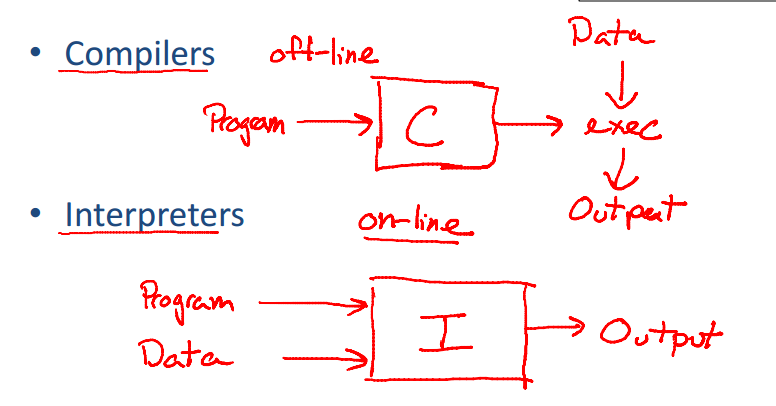
Os compiladores e interpretadores possuem muitas características em comum pois podem executar as mesmas tarefas, como por exemplo, analisar um programa e determinar se ele é válido ou não, porém os interpretadores são um tipo de tradutor no qual, algumas fases do compilador são substituídas por um programa que executa o código produzindo o seu efeito.
Um caso muito interessante é o da linguagem Java que combina compilação e interpretação. Temos o processo de compilação que gera um formato de código chamado de bytecode, e o processo de interpretação feito do bytecode pela Java Virtual Machine ou JVM. Outro detalhe de implementação feito na JVM e em muitos interpretadores é um processo chamado de JIT - Just in Time - que permite que algumas instruções, as mais utilizadas, sejam compiladas para código de máquina a fim de otimizar a sua execução.
O interpretador pode ser divido em dois tipos:
- Interpretador puro: cada instrução é "quebrada" em tokens, analisada, verificada semanticamente e interpretada cada vez que é executada. Como exemplo temos interpretadores de comandos shell.
- Interpretadores mistos: traduzem todo o script em código intermediário e depois interpretam esse código.
Um programa-objeto gerado por um compilador é muito mais rápido do que um programa executado por um interpretador, porém, um interpretador oferece melhores opções para diagnosticar erros, pois executa instrução por instrução.
Estrutura de um compilador
O processo de compilação é muito complexo, existindo uma estrutura básica que divide esse processo em fases, essas fases estão representadas por duas tarefas conhecidas como análise e síntese.
Essa divisão de fases tem como objetivo dar uma visão explicita e detalhada do processo de compilação. A tarefa de análise também chamada de front-end divide o programa fonte em partes e impõe uma estrutura gramatical sobre elas, uma das principais responsabilidades da tarefa de análise é garantir que a sintaxe e semântica do programa fonte estejam corretos. A tarefa de síntese constrói o programa objeto a partir da representação criada na tarefa de análise. A síntese é conhecida como back-end.
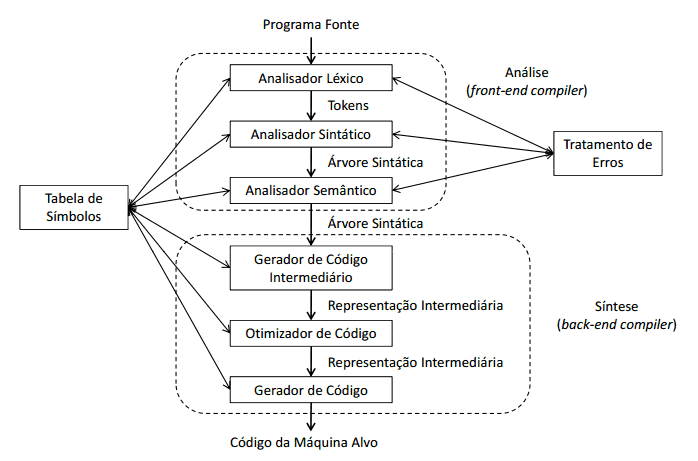
É importante destacar que esse estrutura dividida em seis fases é apenas uma representação didática e tem como objetivo demostrar como o compilador funciona, outras literaturas podem apresentar outros modelos com mais ou menos etapas.
Caso o compilador tenha sido cuidadosamente projeto podemos produzir compiladores de diferentes linguagens fonte para diferentes máquinas alvo, combinando diferentes estruturas de front-end para um único back-end ou um único front-end para diferentes back-ends.
O processo de compilação inicia com o analisador léxico que varre todo o programa fonte e transforma o texto em um fluxo de tokens, e nessa fase é criada a tabela de símbolos. Logo em seguida vem a análise sintática que lê o fluxo de tokens e valida a estrutura do programa criando a árvore sintática. A terceira fase é a análise semântica que é responsável por garantir as regras semânticas. Todas essas fases fazem parte da tarefa de análise.
A próxima fase e a geração de código intermediário, que cria uma abstração do código, logo após vem a fase de otimização do código e por fim, a geração do código objeto que tem como objetivo gerar o código de baixo nível baseado na arquitetura da máquina alvo. Essas fases fazem parte da tarefa de síntese.
Termos
[^1] Desmontador: também chamado de desassembler faz o processo inverso ao montador, ou seja, pega o código de máquina e transforma em código Assembly.
[^2] Mnemônicos: são símbolos que substituem o padrão de bits. Como exemplo o ADD equivale a soma e em bits significa 00100011.
[^3] Tempo de compilação: é o intervalo de tempo de conversão de um programa fonte para um programa objeto. Já o programa objeto é executado no intervalo de tempo chamado tempo de execução.
[^4] Tradutores auto-residentes: ou self-resident translators geram códigos de máquinas hospedeiras nas quais eles mesmos executam.
[^5] Cross-compiling: é o processo de compilação que permite a um compilador compilar um programa para diversos processadores ou arquiteturas.
[ˆ6] Bytecode: é uma representação de código-fonte que será interpretada por uma máquina virtual.
[ˆ7] Açúcar sintático ou Syntactic sugar: É uma forma de tornar uma construção sintática mais expressiva e simples de ler sem afetar seu comportamento.
Estrutura de um Compilador
Os compiladores operem em uma sequencia de fases, cada uma transformando o programa fonte em uma representação para a etapa seguinte. Nesse capítulo vamos ver de uma forma resumida cada etapa do processo de compilação.
Analise Léxica
É a primeira fase do processo de compilação, também é conhecida como leitura ou scanning. O objetivo nessa fase é identificar unidades léxicas ou lexemas que compõem o programa. O analisador léxico lê todos os caracteres do programa fonte e verifica se eles pertencem ao alfabeto da linguagem. Caso um caractere não pertença ao alfabeto da linguagem deve ser gerado um erro léxico.
Os comentários e espaços em branco devem ser ignorados e removidos. Esse processo resulta um conjunto de tokens que são formados por palavras reservadas, identificadores, delimitadores, etc. Nessa etapa é criada a tabela de símbolos.
De uma forma resumida a análise léxica deve quebrar o texto do programa fonte em lexemas, verificar a categoria ao qual eles pertencem e produzir uma sequencia de símbolos léxicos chamados como tokens.
Suponha que tenhamos a seguinte linha de código:
123 x1 ; Y2 true begin
O analisador léxico deve identificar 6 lexemas e a categoria de cada um deles.
| Lexema | Categoria |
|---|---|
| 123 | Número inteiro |
| X1 | Nome de variável |
| ; | Símbolo especial (ponto e vírgula) |
| Y2 | Nome de procedimento |
| true | Constante booleana |
| begin | Palavra reservada |
O analisador léxico deve permitir identificar na linguagem repetições de subconjuntos permitindo que seja possível identificar e classificar esses subconjuntos, por exemplo o subconjunto de palavras reservadas.
Nessa fase o processamento de uma linguagem pode ser feito por gramáticas regulares podendo ser formalmente descrito por expressões regulares. As rotinas que processam essa linguagem modelam algoritmos construídos a partir de autômatos finitos.
Analise Sintática
A analise sintática tem como objeto validar a gramática do programa, nessa etapa o objetivo é reconhecer se a estrutura gramatical do código fonte esta de acordo com as regras sintáticas da linguagem.
Nessa etapa é feita uma varredura na sequência de tokens recebidas do analisador léxico e produzida uma estrutura de dados em formato de árvore conhecida como árvore sintática. A árvore sintática representa a hierarquia do programa fonte. Caso uma construção seja reconhecida com inválida um erro sintético deve ser gerado.
Veja o seguinte trecho de código:
if (a – 10 > b * 2) a = b;
O analisador sintático deve ser capaz de analisar essa linha e de reconhecê-la como válida ou inválida. Para isso ele precisa conhecer a estrutura formada palavra reservada if, a expressão que esta entre ( e ) e o comando de atribuição a = b. Após essa validação deve ser montada a árvore sintática.
A seguinte linha de código:
position = initial + rate * 60
Produz esse árvore sintática.
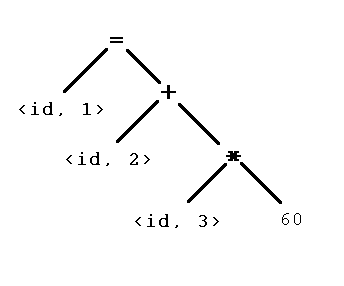
Mesmo com uma boa técnica de detecção de erros o analisador sintático deve ser capaz de recuperá-los e continuar o processo de compilação identificando o maior número possível.
A sintaxe da maioria das linguagens de programação é especificada usando gramáticas livres de contexto que permitem realizar substituições impostas por regras produção e assim validar a estrutura do programa.
Analise Semântica
O objetivo dessa etapa é verificar se a semântica do programa fonte tem consistência. Para isso é utiliza a árvore sintática e as informações contidas na tabela de símbolos.
Por exemplo, a verificação de tipo em uma operação de soma onde cada operando é verificado com cada operador.
Veja:
var a, b: int;
a = b + '2';
Outro exemplo é verificar se um índice em um vetor é um número inteiro.
Pode ser necessário que nessa fase alguns tipos de dados sejam convertidos para outros tipos, essa operação é conhecida como coerção.
Veja o seguinte exemplo:
position = initial + rate * 60
Suponha que a variável position seja declarada como inteiro, nesse caso deverá deve ser identificado um erro de tipo interrompendo o processo de compilação. Caso position, initial e rate sejam declarados como ponto flutuante o inteiro 60 deve ser convertido para ponto flutuante a fim de selecionar corretamente os registradores do processador.
Algum tipos de erros semânticos:
- Tipos de operandos incompatíveis com operadores;
- Identificadores,variáveis e procedimento, não declarados;
- Chamada de funções ou métodos com número incorreto de operadores;
- Comandos fora de contextos, um comando
continuefora de um laço; - Operações de conversão de tipos.
A tabela de símbolos é muito importante nessa etapa pois é através dela que é possível recuperar informações sobre os identificadores que são utilizadas para avaliar as regras semânticas.
Geração de código intermediário
Nesse fase é gerado uma sequência de código denominada código intermediário, que posteriormente em outras fases irá gerar o código objeto. Por ventura essa fase pode não existir e a compilação pode ser feita diretamente para o código objeto, isso é comum em compiladores auto residentes.
E importante destacar que o código intermediário não especifica detalhes da construção do código objeto final.
A representação intermediaria deve ser facilmente produzida e facilmente traduzida para a máquina alvo. Uma forma de representação intermediaria muito conhecida e a forma de três endereços que consistem de três operandos por instrução.
Veja o exemplo:
T1 = inttofloat(60);
T2 = id3 * t1
T3 = id2 + t2
id1 = t3
Essa representação segue o seguinte formato x = y op z onde op é uma operador binário, y e z são endereços para os operandos e x é o endereço para o resultado.
Uma das vantagens de gerar um código intermediário é a possibilidade de obter um código final mais eficiente através da otimização. A representação intermediária deve representar todas as operações do programa.
Otimização de Código
Nessa fase o objetivo é otimizar o código em termos de velocidade de execução e consumo de memória. Essa etapa não depende da arquitetura de máquina e tem como objetivo fazer transformações no código intermediário afim obter um código objeto mais otimizado.
Veja um exemplo de código otimizado.
T1 = id3 * 60.0
id1 = id2 * t1
O número de otimizações irá depender de como o compilador foi implementado, quanto mais otimizações forem realizadas maior o tempo gasto na compilação. Outro detalhe é que a otimização deve reduzir o tempo de execução do programa.
Algumas compiladores permitem que seja parametrizado o nível de otimização, como por exemplo o gcc através das flags de otimização -O2, -O3 por exemplo.
Nos compiladores modernos existe uma etapa chamada de otimização de código dependente de máquina, que permite que as instruções sejam otimizadas para determinada arquitetura de computador.
Geração de código objeto
A geração de código objeto é a última etapa do processo de compilação e recebe como entrada uma representação intermediaria que mapeia a linguagem objeto.
Desse momento deve ser feito a seleção de registradores e reserva de memória para contantes e variáveis. Essa é uma etapa muito importante pois a produção de código objeto eficiente deve ter uma cuidadosa seleção de registradores.
No seguinte trecho de código:
position = initial + rate * 60
Temos como código objeto:
LDF R2, id3
MULF R2, R2 #60.0
LDF R1, id2
ADDF R1, R1, R2
STF id1 R1
O programa objeto reflete as instruções de baixo nível da plataforma que está sendo utilizada, pode-se fazer necessário um gerador de código para cada plataforma.
Após essa fase concluída, para que o programa possa ser executado o código objeto é linkeditado com outros programas objetos ou recursos para posteriormente ser carreado na memória e executado pelo sistema operacional.
Resultado do processo de compilação.
A imagem abaixo exemplifica o processo de compilação divido em etapas. Essas etapas correspondem a estrutura lógica de um compilador e o resultado de cada fase.
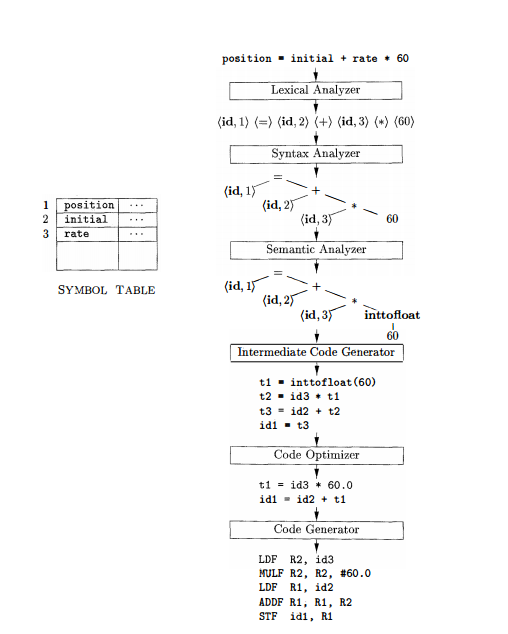
Essa é uma estrutura didática do funcionamento de um compilador, na pratica a distinções em fases não é muito clara, alguns módulos podem ser implementados dentro de outros ou até mesmo nem existirem.
Tabela de símbolos
Durante toda a fase de compilação algumas informações são armazenadas em uma tabela chamada de tabela de símbolos, que nada mais é do que uma estrutura de dodos em forma de lista ou dicionário. As informações coletadas nessa tabela dependem do tipo de tradutor desenvolvido e do programa objeto a ser gerado.
O analisador léxico coleta informações sobre os tokens e seus atributos, para tokens que influenciam decisões de análise gramatical, como por exemplo identificadores, é criado uma entrada na tabela de símbolos, das quais as informações são mantidas para posterior uso.
Os seguintes atributos costumam ser gravados na tabela de símbolos:
- Classe dos identificadores: variável, função, etc.
- Tipo de dado: Inteiro, String, etc.
- Tipos de retornos: no caso de métodos
- Variáveis: tipo, endereço no texto, posição e tamanho.
- Parâmetros formais: tipo do mecanismo de passagem, por valor ou referência.
- Procedimentos/sub-rotinas: número de parâmetros.
A tabela de símbolos é utilizado durante todo o processo de compilação a fim de inserir e extrair informações de forma rápida e eficiente.
Dependendo do linguagem de programacao outras informacoes podem ser gravadas da tabela de simbolos.
Podemos armazenar na tabela de símbolos também informações sobre a linha e coluna que o token foi examinado para em caso de erro o compilador passa informar a posição da falha.
Árvore Sintática
A árvore sintática é uma estrutura de dados em forma de árvore ou grafo que representa sequencia hierarquica da linguagem de programação. Essa esturura permite represetnar cada elemento do programa, os demais passos do compilador consitem em visatar os nos dessa estrutura em uma determinada ordem
Veja uma exemplo de uma sentença if else
Essa representação gráfica é resultante da derivação de uma sentença, cada nó representa uma unidade sintática, formada por um simbolo terminal ou simbolo nao terminal.
Termos
[ˆ1] Sintático: tem o sentido de verificação de forma, estrutura sem referência a significado.
[ˆ2] Semântica: tem o sentido de significado.
[ˆ3] Linkeditor ou Linker: é um programa que reúne módulos compilados e arquivos para criar o programa executável.
[ˆ4] Registradores: são áreas no processador que possuem uma grande velocidade e são utilizados para armazenar valores. Existem vários tipos de registradores com finalidade especificas.
Analise Léxica
A análise léxica também conhecida como scanner ou leitura é a primeira fase de um processo de compilação e sua função é fazer a leitura do programa fonte, caractere a caractere, agrupar os caracteres em lexemas e produzir uma sequência de símbolos léxicos conhecidos como tokens.
A sequência de tokens é enviada para ser processada pela analise sintática que é a próxima fase do processo de compilação .
O analisador léxico deve interagir com a tabela de símbolos inserindo informações de alguns tokens, como por exemplo os identificadores. A nível de implementação a analise léxica normalmente é uma sub-rotina da análise sintática formando um único passo, porem ocorre uma divisão conceitual para simplificar a modularizarão do projeto de um compilador.
Visão geral
A análise léxica pode ser dividida em duas etapas, a primeira chamada de escandimento que é uma simples varredura removendo comentários e espaços em branco, e a segunda etapa, a analise léxica propriamente dita onde o texto é quebrado em lexemas.
Podemos definir três termos relacionados a implementação de um analisador léxico:
-
Padrão: é a forma que os lexemas de uma cadeia de caracteres pode assumir. No caso de palavras reservadas é a sequência de caracteres que formam a palavra reservada, no caso de identificadores são os caracteres que formam os nomes das variáveis e funções.
-
Lexema: é uma sequência de caracteres reconhecidos por um padrão.
-
Token: é um par constituído de um nome é um valor de atributo esse ultimo opcional. O nome de um token é um símbolo que representa a unidade léxica. Por exemplo: palavras reservadas; identificadores; números, etc.
A tabela abaixo mostra os exemplos de uso dos termos durante a análise léxica.
| Token | Padrão | Lexema | Descrição |
|---|---|---|---|
<const, > | Sequência das palavras c, o, n, s, t | const | Palavra reservada |
<while, > | Sequência das palavras w, h, i, l, e | while, While, WHILE | Palavra reservada |
<if, > | Sequência das palavras i, f | If, IF, iF, If | Palavra reservada |
<=, > | <, >, <=, >=, ==, != | ==, != | |
<numero, 18> | Dígitos numéricos | 0.6, 18, 0.009 | Constante numérica |
<literal, "Olá"> | Caracteres entre "" | “Olá Mundo” | Constante literal |
<identificador, 1> | Nomes de variáveis, funções, parâmetros de funções. | nomeCliente, descricaoProduto, calcularPreco() | Nome de variável, nome de função |
<=, > | = | = | Comando de atribuição |
<{, > | {, }, [, ] | {, }, [, ] | Delimitadores de início e fim |
Veja uma série de exemplos relacionados a identificação dos termos.
Exemplo 1
printf("Total = %d\n", score)
onde:
-
printfescoresão lexemas que casam com o padrãoidentificador. -
Total = %d\né um lexema que casa com o padrãoliteral. -
()lexemas que auxiliam a identificação de uma função.
Exemplo 2
const PI = 3.1416
onde:
-
constcasa com o padrãoconstque também é um lexema. -
PIé um lexema que casa com o padrãoidentificador. -
=é um lexema que casa com o padrão do tokenatribuição. -
3.1416é um lexema que casa com o padrão do tokennumero.
Para implementar um analisador léxico é necessário ter uma descrição dos lexemas, então, podemos escrever o código que irá identificar a ocorrência de cada lexema e identificar cada cadeia de caractere casando com o padrão.
Também podemos utilizar um gerador de análise léxica que gera automaticamente o algoritmo para reconhecer os lexemas.
Expressões regulares são um mecanismo importante para especificar os padrões de lexemas.
Tokens
Os tokens são símbolos léxicos reconhecidos através de um padrão.
Os tokens podem ser divididos em dois grupos:
-
Tokens simples: são tokens que não têm valor associado pois a classe do token já a descreve. Exemplo: palavras reservadas, operadores, delimitadores:
<if,>,<else>,<+,>. -
Tokens com argumento: são tokens que têm valor associado e corresponde a elementos da linguagem definidos pelo programador. Exemplo: identificadores, constantes numéricas -
<id, 3>,<numero, 10>,<literal, Olá Mundo>.
Um token possui a seguinte estrutura:
<nome-token, valor-atributo>
Onde o nome do token corresponde a uma classificação do token, por exemplo: numero, identificador, const. E o valor do atributo corresponde a um valor qualquer que pode ser atribuído ao token, por exemplo o valor de entrada na tabela de símbolos.
Exemplo de analise léxica
Suponha que tenhamos o seguinte trecho de código:
total = entrada * saida() + 2
O seguinte fluxo de tokens é gerado.
<id, 15> <=, > <id, 20> <*, > <id,30>, <(>, <)> <+, > <numero, 2>
Temos os seguintes tokens classificados:
<id, 15>: apontador 15 da tabela de símbolos e classe do tokenid.<=, >operador de atribuição, sem necessidade de um valor para o atributo.<id, 20>: apontador 20 da tabela de símbolos e classe do tokenid.<*, >: operador de multiplicação, sem necessidade de um valor para o atributo.<id,30>: apontador 30 da tabela de símbolos e classe do tokenid.<+, >: operador de soma, sem necessidade de um valor para o atributo.<(, >: Delimitador de função.<), >: Delimitador de função.<numero, 2>: token número, com valor para o atributo 2 indicado o valor do número (constante numérica).
A seguir são apresentados alguns exemplos do resultado da análise léxica de um arquivo fonte.
Exemplo 1
Código fonte
while indice < 10 do
indice:= total + indice;
Sequência de tokens
<while,> <id,7> <<,> <numero,10> <do,> <id,7> <:=,> <id,12> <+,> <id, 7> <;, >
Tabela de símbolos
| Entrada | Informações |
|---|---|
| 7 | indice - variável inteira |
| 12 | total - variável inteira |
Exemplo 2
Código fonte
position = initial + rate * 60
Sequência de tokens
<id, 1> <=, > <id, 2> <+, > <id, 3> <*, > <numero, 60>
Tabela de símbolos
| Entrada | Informações |
|---|---|
| 1 | position - variável ponto flutuante |
| 2 | initial - variável ponto flutuante |
| 3 | rate - variável ponto flutuante |
Exemplo 3
Código fonte
a[index] = 4 + 2
Sequência de tokens
<id, 1> <[,> <id, 2> <],> <=,> <numero, 4> <+,> <numero, 2>
Tabela de símbolos
| Entrada | Informações |
|---|---|
| 1 | a - variável inteira |
| 2 | index - variável inteira |
Exemplo 4
Suponha que tenhamos a seguinte linha de código:
position = initial + rate * 60
Mapeamento de tokens.
| Lexema | Símbolo | Significado | Tabela de simbolos | Token |
|---|---|---|---|---|
| position | id | Identificador | 1 | <Idt, 1> |
| = | <=, simbolo> | |||
| initial | id | Identificador | 2 | <Idt, 2> |
| + | <+, operador> | |||
| rate | id | Identificador | 3 | <Idt, 3> |
| * | <*, operador> | |||
| 60 | numero | Inteiro | 4 | <Número, 4> |
Sequência de tokens gerado.
<id, 1> <=> <id, 2> <+> <id, 3> <*> <numero, 4>
Passos para identificar uma sequência de tokens
A análise léxica divide o código fonte em tokens que posteriormente são classificados de acordo com a classe no qual o token pertence. Toda classe tem uma descrição do que ela representa na linguagem de programação.
Veja as etapas para construir um analisador léxico:
- Reconhecer a substring relacionada ao token através de um padrão;
- Partir as strings de entrada em lexemas separando-as do restante dos arquivo fonte; e
- Identificar e classificar o token de cada lexema.
Suponha que tenhamos a seguinte linha de código escrita em linguagem Java:
x = 0
while (x < 10) {
x++;
}
A entrada para o analisador léxico é a seguinte:
x = 0\nwhile (x < 10) {\n\tx++;\n}
Observe a presença do \n e do \t que representam, respectivamente, o caractere Nova Linha e Tabulação.
Com base nesse trecho de código nos podemos concluir que:
- Possui 10 ocorrências de caracteres em branco - incluindo nova linha, tabulação e espaço em branco;
- Possui 1 ocorrência de palavras reservadas;
- Possui 3 ocorrências de identificadores do identificador
x; - Possui 2 ocorrências de números; e
- Possui 7 ocorrências de outros caracteres - representados por
=,(,),{,},++e;.
O analisador léxico realiza tarefas relativamente simples que basicamente agrupam caracteres para formar as palavras que compõem a linguagem de programação.
Erros léxicos
A análise léxica é muito prematura para identificar alguns erros de compilação, veja o exemplo abaixo:
fi (a == “123”) ...
O analisador léxico não consegue identificar o erro da instrução listada acima, pois ele não consegue identificar que em determinada posição deve ser declarado a palavra reservada if ao invés de fi. Essa verificação somente é possível ser feita na análise sintática.
Porem é importante ressaltar que o compilador deve continuar o processo de compilação afim de encontrar o maior número de erros possível.
Uma situação comum de erro léxico é a presença de caracteres que não pertencem a nenhum padrão conhecido da linguagem, como por exemplo o caractere ¢. Nesse caso o analisador léxico deve sinalizar um erro informando a posição desse caractere.
Expressões regulares
-> Expressões regulares ou regex são uma forma simples e flexível de identificar cadeias de caracteres em palavras. Elas são escritas em uma linguagem formal que pode ser interpretada por um processador de expressão regular que examina o texto e identifica partes que casam com a especificação dada, são muito utilizadas para validar entradas de dados, fazer buscas, e extrair informações de textos. As expressões regulares não validam dados, apenas verificam se um texto está em uma determinado padrão. <-
As expressões regulares são formadas por metacarateres que definem padrões para obter o casamento entre uma regex e um texto.
Metacaracteres
São caracteres que tem um significado especial na expressão regular.
Abaixo uma tabela dos principais metacarateres.
| Meta | Descrição | Exemplo |
|---|---|---|
| . | Curinga | Qualquer caractere |
| [] | Lista | Qualquer caractere incluído no conjunto |
| [^] | Lista negada | Qualquer caractere não incluído no conjunto |
| \d | Dígito | O mesmo que [0-9] |
| \D | Não-digito | O mesmo que [^0-9] |
| \s | Caracteres em branco | |
| \S | Caracteres em diferentes de branco | |
| \D | Alfanumérico | O mesmo que [a-zA-Z0-9_] |
| \W | Não-alfanumérico | |
| \ | Escape | Faz com que o caracteres não sejam avaliados na Regex |
| (...) | Grupo | É usado para criar um agrupamento de expressões |
| | | OU | casa | bonita – pode ser casa ou bonita |
Quantificadores
São tipos de metacaracteres que definem um número permitido de repetições na expressão regular.
| Expressão | Descrição | Exemplo |
|---|---|---|
| {n} | Exatamente n ocorrências | |
| {n,m} | No mínimo n ocorrências e no máximo m | |
| {n,} | No mínimo n ocorrências | |
| {,n} | No máximo n ocorrências | |
| ? | 0 ou 1 ocorrência | car?ro – caro ou carro. |
| + | 1,ou mais ocorrência | ca*ro –carro, carrro, carrrro, nunca será caro. |
| * | 0 ou mais ocorrência | ca*ro – caro, carro, carro, carrrro |
Casar
Tem o significado de combinar uma expressão regular com texto, é quando os metacaractres especificados na expressão regular correspondem aos caracteres dos textos.
Veja os exemplos:
-
A regex
\d,\dcasa com9,1já\d,\dnão casa com91. -
A regex
\d{5}-\d{3}é utilizada pra validar CEP. Essa regex casa com os padrões de texto89900-000e87711-000mas não casa com os padrões87711-00077e89900000. A regex é formada pelo metacaractere\de o quantificador{5} -
A regex
[A-Z]{3}\d{4}é utilizada para validar a placa de um automóvel e casa com o padrãoACB1234mas não casa com o padrãoACB12345.
As expressões regulares estão diretamente relacionadas a autômatos finitos não determinístico e são uma alternativa amigável para criar notações de NFA.
As regex são utilizadas por editores de texto, linguagem de programação, programas utilitários, IDE de desenvolvimento e compiladores e seu padrões são independentes de linguagem de programação.
As expressões regulares dão origem a algoritmos de autômatos finito determinísticos e autômatos finitos não determinísticos que são utilizados por analisadores léxicos para reconhecer os padrões de cadeias de caracteres.
Geradores de Analisadores Léxicos
Os geradores de analisadores léxicos e automatizam o processo de criação do autômato finito e o processo de reconhecimento de sentenças regulares a partir da especificação de expressões regulares. Essa ferramentas são comumente chamadas de lex. Atualmente há diversas implementações de lex para diferentes linguagens de programação.
O diagrama abaixo é uma representação de um autômato finito e uma implementação do funcionamento desse autômato.
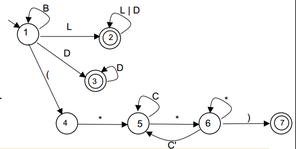

Embora no exemplo seja simples implementar um analisador léxico, essa tarefa podem ser muito trabalhosa, como essa complexidade é frequente na evolução de uma linguagem de programação surgiriam ferramentas que apoiam esse tipo de desenvolvimento.
Existem diversas implementações para gerar analisadores léxicos para diferentes linguagens de programação.
- Flex – http://flex.sourceforge.net/
- JFlex – http://jflex.de/download.html
- Turbo Pascal Lex/Yacc - http://www.musikwissenschaft.uni-mainz.de/~ag/tply/
- Flex++ - http://www.kohsuke.org/flex++bison++/
- CSLex – versão C#, derivada do Jlex - http://www.cybercom.net/~zbrad/DotNet/Lex
A notação ara utilização dessas ferramentas é denominada linguagem lex.
O ponto de partida para a criar uma especificação usando a linguagem lex é criar uma especificação de expressões regulares que descrevem os itens léxicos que são aceitos.
Este arquivo é composto por até três seções:
-
Declarações: Nessa seção se se encontram as declarações de variáveis que representam definições regulares dos lexemas.
-
Regras de Tradução: Nessa seção são vinculada regras que correspondentes a ações em cada expressão regular valida na linguagem.
-
Procedimentos Auxiliares: Esta é a terceira e última seção do arquivo de especificação. Nela são colocadas as definições de procedimentos necessários para a realização das ações especificadas ou auxiliares ao analisador léxico
As regras de tradução são expressas no seguinte formato
Padrão { Ação }
onde: Padrão é uma expressão regular que pode ser reconhecida pelo
analisador léxico Ação é um fragmento de código que vai se invocado quando a expressão é reconhecida.
Os geradores de analisadores léxicos geram rotinas para fazer a análise léxica de uma linguagem de programação a partir de um arquivo de especificações contendo basicamente expressões regulares que descrevem os tokens. Essas rotinas representam algoritmos de autômatos finitos - DFA e NFA.
É possível fazer a identificação de cada token através do seu padrão, após esse processo é gerado um arquivo fonte com a implementação do analisador léxico baseado em uma autômato finito que transforma os padrões de entrada em um diagrama de estados de transição.
Termos
[ˆ1] - Autômato finito: Envolvem estados e as transições entre estados de acordo com a determinadas entradas.
[ˆ2] - Autômato finito determinístico - DFA: É um autômato finito onde cada símbolo de entrada possui no máximo uma saída, ou seja, para cada entrada existe um estado onde o pode transitar a partir de seu estado atual.
[ˆ3] - Autômato finito não determinístico - NFA: É um autômato finito onde um símbolo de entrada tem duas ou mais saídas, ou seja, pode estar em vários estados ao mesmo tempo, isso possibilita ao algoritmo tentar adivinhar algo sobre a entrada.
[^4] - Expressões regulares - é uma notação - linguagem - utilizada para descrever padrões em cadeias de caracteres quer podem ser representadas por autômatos finitos.
Analise Sintática
O Analisador sintático também conhecido como parser tem como tarefa principal determinar se o programa de entrada representado pelo fluxo de tokens possui as sentenças válidas para a linguagem de programação.
A analise sintática e a segunda etapa do processo de compilação e na maioria dos casos utiliza gramáticas livres de contexto para especificar a sintaxe de uma linguagem de programação.
Visão geral
A sintaxe é a parte da gramática que estuda a disposição das palavras na frase e das frases em um discurso. Essa etapa no processo de compilação deve reconhecer as forma do programa fonte e determinar se ele é valido ou não.
Esse modelo pode ser definido utilizando gramáticas livres de contexto que representam uma gramática formal e pode ser escrita através de algoritmos fazem a derivação de todas as possíveis construções da linguagem.
As derivações tem como objetivo determinar se um fluxo de palavras se encaixa na sintaxe da linguagem de programação.
Alguns termos utilizados na definição de linguagens de programação.
- Símbolo: são os elementos mínimos que compõe uma linguagem. Na linguagem humana são as letras.
- Sentença: É um conjunto ordenado de símbolos que forma uma cadeia ou string. Na linguagem humana são as palavras.
- Alfabeto: É um conjunto de símbolos. Na linguagem humana é o conjunto de letras {a, b, c, d, ...}
- Linguagem: É o conjunto de sentenças, Na linguagem humana são os conjuntos de palavras {compiladores, linguagem, ...}
- Gramática: É uma forma de representar as regras para formação de uma linguagem.
Trazendo esse conceito para linguagem de programação temos:
- Alfabeto: {w, h, i, l, e, +, 1, 2, 3}
- Símbolos: 1, 5, +, w
- Sentença: while, 123, +1
- Linguagem: {while, 123, +1}
Dada uma gramática G e uma sentença s o objetivo do analisador sintático é verificar se a sentença s pertence a linguagem G. O analisador sintático recebe do analisador léxico a sequência de tokens que constitui a sentença s e produz uma arvore de derivação se a sentença é válida ou emite um erro se a sentença é inválida.
O analisador léxico é desenvolvido para reconhecer cadeias de caracteres fazendo uma leitura dos caracteres e obtendo a sequência de tokens, esse analisador vê o texto como uma sequência de palavras de uma linguagem regular e reconhece ele através de autômatos finitos determinísticos e não determinísticos.
Já o analisador sintático vê o mesmo texto como uma sequência de sentenças que deve satisfazer as regras gramaticais. É através da gramática que podemos validar expressões criadas na linguagem de programação.
O analisador sintático agrupa os tokens em frases gramaticais usadas pelo compilador com o objetivo de criar uma saída que representa a estrutura hierarquia do programa fonte.
Veja no quadro abaixo as especificações de entrada e saída das etapas vistas até o momento:
| Fase | Entrada | Saída |
|---|---|---|
| Lexer | Conjunto de caracteres | Conjunto de tokens |
| Parser | Conjunto de tokens | Árvore sintática |
Observe a estrutura sintática de uma linguagem de programação. Temos as divisões dos blocos, compostos por comandos, compostos por expressões.
Entende-se por regras gramáticas as formas como podemos descrever a estrutura sintática do programa.
Veja um exemplo no diagrama abaixo demostrando esse processo de compilação visto das etapas estudadas até o momento.
Descubra os erros sintáticos do código fonte abaixo escrito em linguagem Java.

- Na linha 06 a falta do colchete.
- Na linha 03 o ponto e vírgula marcando o final do comando.
- Na linha 01 a virgula separando os parâmetros.
E importante destacar que a árvore de derivação representa toda a estrutura sintática do programa.
Gramática Livre de Contexto - GLC
As linguagens de programação em geral pertencem a uma categoria chamada de Linguagens Livres de Contexto. Umas das formas de representar essas linguagens é através de Gramáticas Livres de Contexto que são a base para a construção de analisadores sintáticos. Elas são utilizadas para especificar as regras sintáticas de uma linguagem de programação, uma linguagem regular pode ser reconhecida por uma automato finitos determinísticos e não determinísticos, já uma Gramatica Livre de Contexto pode ser reconhecida por um automato de pilha.
Outra aplicação de GLC são os DTD - Definição de Tipos de Documentos - utilizados por arquivos XML que descreve as tags de uma forma natural, as tags deve estar aninhas afim de lidar com o significado do texto.
Veja o exemplo:
<produto><codigo</codigo></produto>
Uma gramática descreve naturalmente como é possível fazer construções no programa. Veja o exemplo de um comando if-else em Pascal que deve ter a seguinte forma.
if (expressão) then declaração else declaração ;
Essa mesma forma em uma Gramática Livre de Contexto pode ser expressada da seguinte maneira:
declaração → if ( expressão ) then declaração else declaração ;
A definição formal de uma gramática livre de contexto pode ser representada através dos seguintes componentes:
G = (N, T, P, S)
Onde:
- N – Conjunto finito de símbolos não terminais.
- T – Conjunto finito de símbolos terminais.
- P – Conjunto de regras de produções.
- S – Símbolo inicial da gramática.
Terminologias:
-
Símbolos terminais: Conjunto finito de símbolos básicos que formam as palavras da linguagens, são representadas pelo tokens reconhecidos pelo analisador lexico.
-
Símbolos não terminais: Conjunto finito de variáveis utilizadas para representar os conjuntos da linguagem, são formadas pelos terminas e pelos próprios símbolos não terminais.
-
Símbolo inicial: É a variável, simbolo não terminal, que representa o inicio da definição da linguagem.
-
Regras de produções: Representa um conjunto de regras sintáticas que representam a definição da linguagem, indicam como símbolos terminais e não terminais podem ser combinados.
As regras de produção são representadas da seguinte forma:
{A} → {α}
Onde:
- A é uma variável - simbolo não terminal.
- -> simbolo de produção .
- α é a combinação símbolos terminais e não terminais que representam a forma como uma string vai ser formada.
Veja o exemplo de uma Gramatica Livre de Contexto.
G = ({S}, {a, b}, P, S)
P = {
S → aSb
S → λ
}
Essa gramatica é formada pelas terminais a e b, que são os tokens da linguagem, como regras de produção nos temos aSb que obriga ter um a e b nas extremidades da palavras, o simbolo λ que significa vazio.
Derivações
A derivação é a substituição do conjunto de símbolos não terminais por símbolos terminais começando pelo símbolo inicial, ao final desse processo o resultado é a forma como a linguagem deve assumir.
Durante a derivação devemos aplicar as regras de produção para substituir cada simbolo não terminal por um simbolo terminal, isso permite identificar se certa cadeias de caracteres pertence a linguagem, as regras expandem todas as produções possíveis. Como resultado desse processo temos a árvore de derivação.
Tipos de derivação:
-
Top-Down:Examina os símbolos terminais da esquerda para a direita - forma a árvore sintatica de cima para baixo.
- L(eft-to-right) L(eft-most-derivation) => LL
-
Bottom-Up: Examina os símbolos terminais da direita para a esquerda - forma a árvore sintatica de baixo para cima
- S(imple) L(eft-to-right) R(ight-most-derivation) => SLR
- L(eft-to-right) R(ight-most-derivation) => LR
- L(ook) A(head) L(eft-to-right) R(ight-most-derivation) => LALR

Independente do algortimo utilizado a derivação deve produzir o mesmo resultado, ou seja, a mesma árvore de derivação, caso o resultado seja diferente temos uma ambiguidade.
Árvore de derivação
É uma estrutura em formato de árvore que representa a derivação de uma sentença ou conjunto de sentenças, essa estrutura ira gera a árvores de analise sintática que representa o programa fonte, e é o resultado da analise sintática, essa estrutura facilita é muito utilizada nas etapas seguinda da compilação.
E importante ressaltar que a árvore de análise sintática esta diretamente relacionada a existência de derivações.
Dada a seguinte GLC:
G = ({S}, {a, b}, P, S)
P = {
S → aSb
S → λ
}
Como resultado temos a seguinte árvore de derivação:
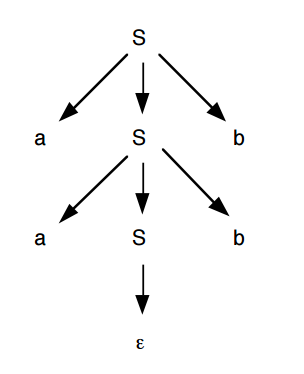
A raiz da arvore de derivação é sempre o simbolo inicial, os vértices interiores são os símbolos não terminais, os símbolos terminais são as folhas.
Ambiguidade:
Certas gramaticas permitem que uma mesma sentença tenha mas de uma árvore de derivação, isso torna a gramática inadequada para a linguagem de programação, pois o compilador não pode determinar a estrutura desse programa fonte. Duas derivações podem gerar uma unica árvore sintática, mas duas árvores sintáticas não podem ser geradas por uma derivacao.
Uma ambiguidade por ser evitada de duas formas:
- Reescrevendo a gramatica afim de remover a ambiguidade, isso pode tornar a gramatica mais complexa.
- Definir ordens de prioridade durante a derivação.
Veja um exemplo de uma gramática ambigua.
Dada a seguinte gramatica utilizada para reconhecer as principais operações aritméticas:
G = ({E}, {+, *, (, ), x}, P, E)
p {
E → E + E
E → E * E
E → (E)
E → x
E → λ
}
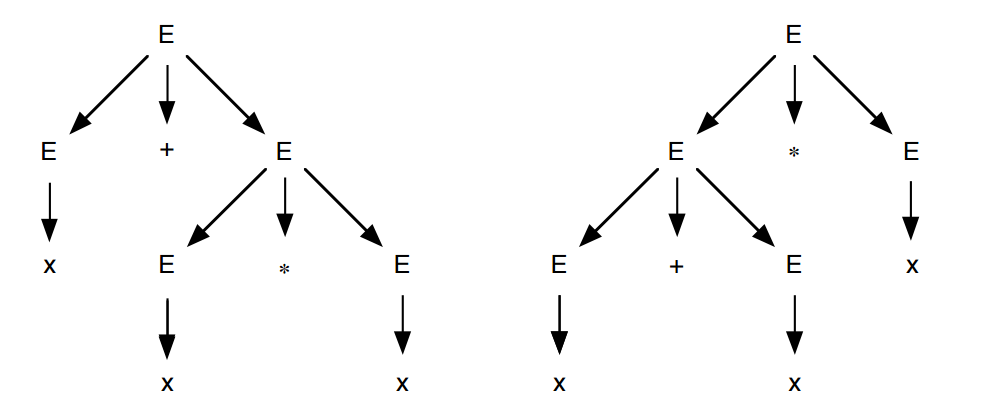
Suponha que queremos validar a seguinte sentença x + x * x.
• Derivação mais à esquerda ∗ E ⇒ E+E ⇒ x+E ⇒ x+E∗E ⇒ x+x∗E ⇒ x+x∗x
• Derivação mais à direita ∗ E ⇒ E∗E ⇒ E∗x ⇒ E+E∗x ⇒ E+x∗x ⇒ x+x∗x
Observe que duas árvores sintáticas foram geradas para essa sentença, logo temos uma ambiguidades.
Reescrevendo essa gramatica para evitar a ambiguidade, temos o seguinte resultado.
G = ({E}, {+, *, (, ), x}, P, E)
P {
E → T + E | T
T → x * T
E → x
E → (E) * T
E → (T)
E → λ
}
Não existe algoritmo capaz de eliminar a ambiguidade, nesses casos é necessário aplicas a técnicas de eliminação de ambiguidade.
Forma de Backus-Naur (BNF)
A Forma de Backus-Naur é outra maneira de representar linguagens livres de contexto, são muito semelhantes as GLC mas possuem duas importantes diferenças quando comparamos com GLCs.
- O sinal
→é substituído por::=. Ex:S → α≡S ::= α. - Os símbolos não terminais devem esta entre
<e>.
Veja o exemplo

Veja uma comparação entre as duas formas gramaticais
Gramatica livre de contexto
G ({S, M, N}, {x,y}, P, S)
P {
S → x | M
M → MN | xy
N → y
}
Forma de Backus-Naur
G = ({<S>, <M>, <N>}, {x,y}, P, <S>)
<S> ::= x | <M>
<M> ::= <M> <N> | xy
<N> ::= y
Os símbolos <, >, ::= não fazem parte da linguagem
Forma Estendida de Backus-Naur (BNF)
É um complemento da Forma de Backus-Naur que permite que no lado direto da produção seja possível ter operadores. Isso facilita a escrita das regras gramaticais pois elas ficam mais simples.
Os seguintes operadores pode ser utilizados:
Seleção:
(α | β) um dos elementos entre parenteses pode ser expressos
<S> ::= a(b | c | d)e
Pode assumir as seguintes derivações:
abe
ace
ade
Opcional:
[α] o que estiver entre colchetes pode ter utilizado ou não
<S> ::= a[bcd]e
Pode assumir as seguintes derivações:
ae
abcde
Repetição 0 ou mais vezes:
(α)* o que estiver entre parentese pode repetir um numero qualquer de vezes e pode não ser usado
<S> ::= a(b)*c
Pode assumir as seguintes derivações:
ac
abc
abbc
abbc
abbb...c
Repetição 1 ou mais vezes:
(α)+ o que estiver entre parentese pode repetir um numero qualquer de vezes
<S> ::= a(b)+c
Pode assumir as seguintes derivações:
abc
abbc
abbc
abbb...c

Outro tipo de notação usuada para representar gramáticas é a notação de grafos sintáticos. Esta notação tem o mesmo poder de expressão de BNF, porém define uma representação visual para as regras de uma gramática livre de contexto.
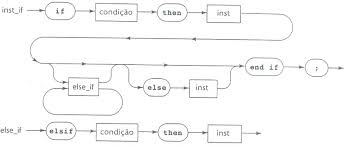
Na notação de grafos sintáticos, símbolos terminais são representados por círculos e símbolos não-terminais por retângulos. Setas são utilizadas para indicar a seqüência de expansão de um símbolo não-terminal.
Predictive Parsing - (Top-Down)
Nos seção vamos apresentar vários exemplos de GLC, como podemos criar uma GCL, aplicar as regras de derivação utilizando o método top-down e montar a árvore de derivação.
Dicas para criar uma gramática livre de contexto:
- Conhecer todos os tokens;
- Especificar a gramática. Por exemplo
G = ( {A, B, C}, {int, id, numero, +, -}, P, A ); - Criar as regra de produção;
- Fazer a derivação;
É comum representar os o símbolos terminais em maiúsculo e o símbolos não terminais em minusculo.
Na parte 2 desse e-book é apresentado o software JFLAP que pode ser utilizado para criar GLC e fazer as derivações a fim de entender melhor esse conceito.
Exemplo 01 – Linguagem ab
Definir a gramática:
G = ({S}, {a, b}, P, S)
P {
S → aSb
S → λ
}
Identificação terminologias:
| Descrição | |
|---|---|
| Símbolos terminais | a, b |
| Símbolos não terminais: | S |
| Símbolo inicial: | S |
| Regra de produção: | P |
A palavra aabb pode ser gerada a partir da seguinte derivação:
1 → aSb
2 → aaSbb
3 → aabb
Com a gramática acima é possível dizer que palavra aab pertence linguagem?
Exemplo 02 Linguagem ab estendida
Definir da gramática:
G = ({A, B, S}, {a, b}, P, S)
P {
S → AB
A → aA
B → bB
A → λ
B → λ
}
Identificação terminologias:
| Descrição | |
|---|---|
| Símbolos terminais | a, b |
| Símbolos não terminais: | S, A, B |
| Símbolo inicial: | S |
| Regra de produção: | P |
A palavra abb pode ser gerada a partir da seguinte derivação:
1 → AB
2 → aAB
3 → abB
4 → abb
Com a gramática acima é possível dizer que palavra a pertence linguagem?
E o b pertence a linguagem?
Exemplo 03 Linguagem ab com restrições
Definir da gramática:
G = ({S, A, B}, {a, b}, P, S)
P {
S → aaAb
A → aA
A → λ
}
Identificação terminologias:
| Descrição | |
|---|---|
| Símbolos terminais | a, b |
| Símbolos não terminais: | S, A, B |
| Símbolo inicial: | S |
| Regra de produção: | P |
A palavra aaab pode ser gerada a partir da seguinte derivação:
1 → aaAb
2 → aaaAb
3 → aaab
Com a gramática acima é possível dizer que palavra abb pertence linguagem?
E o aabb pertence a linguagem?
Exemplo 03 Linguagem a
Definir da gramática:
G = ({S, A, B, C}, {a}, P, S)
P {
S → aA
A → aB
B → aC
C → λ
}
Identificação terminologias
| Descrição | |
|---|---|
| Símbolos terminais | a |
| Símbolos não terminais: | S, A, B, C |
| Símbolo inicial: | S |
| Regra de produção: | P |
Olhando para esse gramatica nos podemos concluir que ela somente gerar linguagem formas por a.
Exemplo 04 – Expressões matemáticas
Definir da gramática:
G = ({E, T}, {+, -, *, /, (, ), x}, P, E)
P {
E → E + T
E → E - T
E → T
T → T * F
T → T / F
T → F
F → (E)
F → x
}
Identificação terminologias
| Descrição | |
|---|---|
| Símbolos terminais | +, -, *, /, (, ), x |
| Símbolos não terminais: | E, T |
| Símbolo inicial: | E |
| Regra de produção: | P |
A expressão (x + x) * x pode ser derivada a partir da seguinte regra de produção:
1 → T
2 → T * F
3 → F * F
4 → (E) * F
5 → (E + T) * F
6 → (E + T) * F
7 → (T + T) * F
8 → (F + T) * F
9 → (x + T) * F
10 → (x + F) * F
10 → (x + x) * F
11 → (x + x) * x
É possível derivar a expressão x - x?
Exemplo 04 – Chamada de funções
Definir a gramática:
G = ({S, X, Y, Z}, {(, ), , , id}, P, S)
OPR {
S → id(X)
X → Y
Y → Y, Z
Y → Z
Z → id
X → λ
}
Identificação terminologias:
| Descrição | |
|---|---|
| Símbolos terminais | (,), ,, ,id |
| Símbolos não terminais: | S, X, Y, Z |
| Símbolo inicial: | S |
| Regra de produção: | P |
Derivação da sentença exibir(valor, desconto):
1 → exibir(X)
2 → exibir(Y)
3 → exibir(Y, Z)
4 → exibir(Z, Z)
5 → exibir(valor, Z)
6 → exibir(valor, desconto)
Também é possível derivar print(nome) e print()?
Geradores de analisadores sintáticos
Da mesma forma que ocorre na construção de analisadores léxicos os analisadores sintáticos podem ser construídos através de ferramentas que auxiliam esse trabalho.
O funcionamento é semelhante aos analisadores léxicos. Um arquivo com as especificações sintáticas é criado e através de comandos o analisador sintático é gerado.
A saída é um arquivo de código com a implementação do analisador sintático.
Analise Semântica
Até o momento vimos as etapas de análise léxica, que quebra o programa fonte em tokens e a analise sintática, que valida as regras a sintaxe da linguagem de programação.
Não é possível representar com expressões regulares ou com uma gramática livre de contexto regras como: todo identificador deve ser declarado antes de ser usado. Muitas verificações devem ser realizadas com meta-informações e com elementos que estão presentes em vários pontos do código fonte, distantes uns dos outros. O analisador semântico utiliza a árvore sintática e a tabela de símbolos para fazer as analise semantica.
A analise semântica é responsavel por verificar aspectos relacionados ao significado das instruções, essa é a terceira etapa do processo de compilação e nesse momento ocorre a validação de uma serie regras que não podem ser verificadas nas etapas anteriores.
É importante ressaltar que muitos dos erros semanticos tem origem de regras dependentes da linguagem de programacao.
As validações que não podem ser executadas pelas etapas anteriores devem ser executadas durante a análise semântica a fim de garantir que o programa fonte estaja coerente e o mesmo possa ser convertido para linguagem de máquina.
A análise semântica percorre a árvore sintática relaciona os identificadores com seus dependentes de acordo com a estrutura hierarquica.
Essa etapa também captura informações sobre o programa fonte para que as fases subsequentes gerar o código objeto, um importante componente da analise semântica é a verificação de tipos, nela o compilador verifica se cada operador recebe os operandos permitidos e especificados na linguagem fonte.
Um exemplo que ilustra muito bem essa etapa de validação de tipos é a atribuição de objetos de tipos ou classe diferentes. Em alguns casos, o compilador realiza a conversão automática de um tipo para outro que seja adequado à aplicação do operador. Por exemplo a expressão.
var s: String;
s := 2 + ‘2’;
Veja o exemplo de um código em Object Pascal:
function Soma(a, b : Integer) : Integer;
var
i : Integer;
begin
i := a + b;
Result := i;
end;
No exemplo acima o analisador semântico de ter uma série de preocupações para validar o significado de cada regra de produção.
Vamos utilizar como exemplo a regra de atribuição:
i := a + b;
- O identificador
ifoi declarado? - O identificador
ié uma variável? - Qual o escopo da variável
i? - Qual é o tipo da variável
i? - O tipo da variável
ié compatível com os demais identificadores, operadores?
Os tipo de dados são muito importantes nessa etapa da compilação, eles são uma notações que as linguagens de programação utilizam para representar um conjunto de valores. Com base nos tipos o analisador semântico pode definir quais valores podem ser manipulados, isso é conhecido com type checking.
Inferência de tipos
O sistema de tipos de dados podem ser divididos em dois grupos: sistemas dinâmicos e sistemas estáticos. Muitas das linguagens utilizam o sistema estático, esse sistema é predominante em linguagens compiladas, pois essa informação é utilizada durante a compilação e simplifica o trabalho do compilador.
- Sistema de tipo estático: Linguagem como C, Java, Pascal obrigam o programador a definir os tipos das variáveis e retorno de funções, o compilador pode fazer varias checagens de tipo em tempo de compilação.
- Sistema de tipo dinâmico: Variáveis e retorno de funções não possuem declaração de tipos, como exemplo temos linguagens como Python , Perl e PHP.
Algumas linguagens utilizam um mecanismo muito interessantes chamado inferência de tipos, que permite a uma variavel assumir varios tipos durante o seu ciclo de vida, isso permite que a ela possa ter varios varios valores. Linguagens de programação como Haskel tira proveito desse mecanismo. Nesses casos o compilador infere o tipo da variável em tempo de execução, esse tipo de mecanismos esta diretamente relacionado ao mecanismo de Generics do Java e Delphi Language. A validação de tipos passa a ser realizada em tempo de execucao.
Principais erros semânticos:
Escopo dos identificadores
O compilador deve garantir que variáveis e funções estejam declaradas em locais que podem ser acessados onde esses identificadores estão sendo utilizados.
Uma classe com funções declaradas como privadas e essas funções sendo utilizadas fora da classe.
class Foo {
private $x;
private function sum() {
return $this->x = 1;
}
}
Foo().sum()
Veja o exemplo da variável contador, ele deve ser declarada em cada escopo onde esta sendo utilizada.
def foo():
cont = 0
def bar():
cont = 1
def dop():
cont = 3
bar()
dop()
print(cont)
Compatibilidade de tipos:
Verificar se os tipos de dados declarado nas variáveis e funções estão sendo utilizados e atribuidas corretamente, por exemplo: operações matemáticas devem ser realizadas com números, atribuições de valores para variávies.
Variável declaração como int está recebendo um valor string.
var i : int;
var s : string;
s = "john";
i := f;
No código acima qual é o comportamento em uma linguagem interpretada como Python? E no Pascal que é compilado?
Em alguns casos pode ser efetuada a conversão de tipos, essa operacao é conhecida como cast, e pode ser feito de forma explicita no código ou pelo proprio compilador.
Detectar unicidade de nomes de identificadores:
Essa verificação é muito importante pois ele deve garantir que os identificadores sejam unicos não havendo na tabela de simbolos uma entrada para o mesmo identificador:
Isso implica em:
- diferentes identificadores podem ter o mesmo nome;
- o mesmo identificadores pode estar em um escopo diferente;
- sobrecarga de metodos deve gerar novas entradas na tabela de simbolos;
var i : int;
var i : int64;
var foo int
func foo() {
fmt.Println(math.pi)
}
Detectar o uso correto de comandos de controle de fluxo:
Comandos como continue e break executam saltos na execucao de códigos, esse comandos deve ser utilizados em instruções que permitem os saltos.
Introdução
O estudo de compiladores deve misturar teoria e prática, é importante entender todos os componentes envolvidos nesse processo e como podemos implementar cada um deles.
Nessa parte do ebook nós vamos aplicar os conhecimentos adquiridos até o momento utilizando ferramentas e escrevendo algoritmos relacionados a componentes do projeto de um compilador.
Construindo o primeiro analisador léxico com JFlex
JFlex é um gerador de analisador léxico escrito em Java. Ele recebe como entrada uma especificação baseada em um conjunto de expressões regulares e gera um algoritmo que lê os caracteres descritos no arquivo arquivo fonte combinando com os padrões definidos na especificação.
Instalando o JFlex
Faça o download do JFlex nesse link: http://jflex.de/download.html
Nesse primeiro exemplo nós vamos usar o JFlex integrado com a IDE Eclipse.
Você deve fazer a instalação da biblioteca no seu ambiente de desenvolvimento, eu sugiro uma rápida leitura nas instruções de instalação nesse link.
Você pode adicionar a biblioteca jflex-1.6.1.jar na configuração de Build Path do seu projeto no Eclipse.
Criado uma analisador léxico
Crie um novo projeto no Eclipse através do menu File -> New -> Java Project chamado lexicalanalyzer e adicione a biblioteca do JFlex - jflex-1.6.1.jar - nas configurações de Build Path do projeto. Você também deve crair uma pacote chamado br.com.johnidouglas.
Se preferir você pode criar um projeto usando o Maven e adicionar a seguinte dependência.
No campo Group Id informe br.com.johnidouglas e no campo Artifact Id informe lexicalanalyzer
<dependency>
<groupId>de.jflex</groupId>
<artifactId>jflex</artifactId>
<version>1.6.1</version>
</dependency>
Essa imagem mostra a estrutura do projeto no Eclipse.
Em seguida vamos criar a classe que ira gerar o analisador léxico a cada nova alteração no arquivo de especificação. Isso evita o uso da linha de comando para gerar a classe Java responsável por implementar o algoritmo de reconhecimento de tokens.
Vamos chamar essa classe de Generator.
package br.com.johnidouglas.lexicalanalyzer;
import java.io.File;
import java.nio.file.Paths;
public class Generator {
public static void main(String[] args) {
String rootPath = Paths.get("").toAbsolutePath(). toString();
String subPath = "/src/main/java/br/com/johnidouglas/lexicalanalyzer/";
String file = rootPath + subPath + "language.lex";
File sourceCode = new File(file);
jflex.Main.generate(sourceCode);
}
}
O arquivo especificação possui as definições da nossa linguagem de programação. Para criar esse arquivo na IDE do Eclipse vá em File -> New -> Other -> File salve esse arquivo com o nome de language.lex na raiz do projeto.
No arquivo digite o seguinte conteúdo.
package br.com.johnidouglas.lexicalanalyzer;
%%
%{
private void imprimir(String descricao, String lexema) {
System.out.println(lexema + " - " + descricao);
}
%}
%class LexicalAnalyzer
%type void
BRANCO = [\n| |\t|\r]
ID = [_|a-z|A-Z][a-z|A-Z|0-9|_]*
SOMA = "+"
INTEIRO = 0|[1-9][0-9]*
%%
"if" { imprimir("Palavra reservada if", yytext()); }
"then" { imprimir("Palavra reservada then", yytext()); }
{BRANCO} { imprimir("Espaço em branco", yytext()); }
{ID} { imprimir("Identificador", yytext()); }
{SOMA} { imprimir("Operador de soma", yytext()); }
{INTEIRO} { imprimir("Número Inteiro", yytext()); }
. { throw new RuntimeException("Caractere inválido " + yytext()); }
Pronto, nós já temos um analisador léxico onde é possível reconhecer um conjunto de lexemas baseado em padrões definidos no arquivo de especificação - language.lex, agora nos precisamos testar o analisador léxico.
Para isso crie uma nova classe chamada LanguageSextaFase e inclua o seguinte código nela.
package br.com.johnidouglas.lexicalanalyzer;
import java.io.IOException;
import java.io.StringReader;
public class LanguageSextaFase {
public static void main(String[] args) throws IOException {
String expr = "if 2 + 3+a then";
LexicalAnalyzer lexical = new LexicalAnalyzer(new StringReader(expr));
lexical.yylex();
}
}
Para executar o analisador léxico siga os seguintes passos:
-
Execute a classe Generator: Observe que no projeto foi criado a classe
LexicalAnalyzer. Essa classe possui a implementação das regras definidas no arquivo de especificaçãolanguage.lexé representa o algoritmo do analisador léxico. -
Execute a classe
LanguageSextaFase: Essa classe vai executar o analisador léxico passando como parametro uma expressão de uma lingaugem de programação qualquer.
Observe que a saída será do analisador léxico será a seguinte.
if - Palavra reservada if
- Espaço em branco
2 - Número Inteiro
- Espaço em branco
+ - Operador de soma
- Espaço em branco
3 - Número Inteiro
+ - Operador de soma
a - Identificador
- Espaço em branco
then - Palavra reservada then
Baseado nesse primeiro exercício nos implementamos a primeira etapa do processo de compilação utilizado um gerando de analisador léxico.
Construindo uma analisador léxico para a linguagem Pascal
Vamos aprimorar o nosso analisador léxico para que ele reconheça os tokens pertencentes a linguagem de programação Pascal.
Essa imagem mostra a estrutura do projeto no Eclipse.
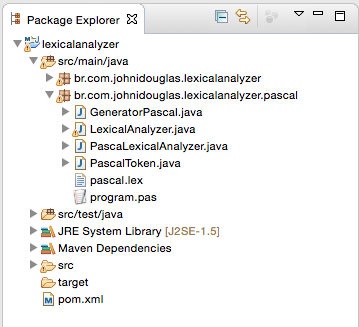
Crie uma classe chamada GeneratorPascal, para isso você deve criar um novo pacote Java dentro do projeto lexicalanalyzer, vamos chamar esse pacote de pascal - br.com.johnidouglas.lexicalanalyzer.pascal .
A classe GeneratorPascal deve ter a seguinte implementação.
package br.com.johnidouglas.lexicalanalyzer.pascal;
import java.io.File;
import java.nio.file.Paths;
public class GeneratorPascal {
public static void main(String[] args) {
String rootPath = Paths.get("").toAbsolutePath(). toString();
String subPath = "/src/main/java/br/com/johnidouglas/lexicalanalyzer/pascal/";
String file = rootPath + subPath + "pascal.lex";
File sourceCode = new File(file);
jflex.Main.generate(sourceCode);
}
}
Agora vamos criar um arquivo de código chamado program.pas esse arquivo vai conter o código fonte do programa escrito em Pascal.
// Programa que cálcula o salário de funcionários
Program CalcularSalario;
Var TempoEmAnos : Integer;
Var ValorSalario: Real;
Begin
If (TempoEmAnos > 10) Then
ValorSalario := 100.00;
Else
ValorSalario := ValorSalario * 2;
End;
Imprimir("Processamento feito com sucesso")
End.
Vamos criar uma classe chamada PascalToken essa classe vai representar um token reconhecido na linguagem e deve ter duas propriedades, name, value, line e column.
package br.com.johnidouglas.lexicalanalyzer.pascal;
public class PascalToken {
public String name;
public String value;
public Integer line;
public Integer column;
public PascalToken(String name, String value, Integer line, Integer column) {
this.name = name;
this.value = value;
this.line = line;
this.column = column;
}
}
Crie uma classe chamada PascaLexicalAnalyzer com o seguinte código.
package br.com.johnidouglas.lexicalanalyzer.pascal;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths;
public class PascaLexicalAnalyzer {
public static void main(String[] args) throws IOException {
String rootPath = Paths.get("").toAbsolutePath(). toString();
String subPath = "/src/main/java/br/com/johnidouglas/lexicalanalyzer/pascal";
String sourceCode = rootPath + subPath + "/program.pas";
LexicalAnalyzer lexical = new LexicalAnalyzer(new FileReader(sourceCode));
PascalToken token;
while ((token = lexical.yylex()) != null) {
System.out.println("<" + token.name + ", " + token.value + "> (" + token.line + " - " + token.column + ")");
}
}
}
Essa classe é responsável por executar o analisador léxico.
Nos precisamos criar o arquivo que vai conter as especificações da linguagem de programação Pascal para que os tokens sejam reconhecidos.
Crie o arquivo pascal.lex esse arquivo deve conter a seguinte especificação.
package br.com.johnidouglas.lexicalanalyzer.pascal;
import java_cup.runtime.*;
%%
%{
private PascalToken createToken(String name, String value) {
return new PascalToken( name, value, yyline, yycolumn);
}
%}
%public
%class LexicalAnalyzer
%type PascalToken
%line
%column
inteiro = 0|[1-9][0-9]*
brancos = [\n| |\t]
program = "program"
%%
{inteiro} { return createToken("inteiro", yytext()); }
{program} { return createToken(yytext(), "");}
{brancos} { /**/ }
. { throw new RuntimeException("Caractere inválido " + yytext() + " na linha " + yyline + ", coluna " +yycolumn); }
O processo para executar o analisador léxico e o mesmo já utilizado no primeiro exemplo.
-
Execute a classe
GeneratorPascalessa classe é responsável por gerar o algoritmo do analisador léxico. -
Execute a classe
PascaLexicalAnalyzeressa classe é responsável por executar o analisador léxico.
Você deve ter percebido que alguns erros ocorreram, isso por que nosso arquivo de especificação esta incompleto, ou seja, não possui todos os tokens da linguagem Pascal.
Você deve implementar o restante da especificação do Pascal através de expressões regulares.
Construindo um Compilador Front-End com JFlex e Java CUP
Para integrar com o analisador léxico criado através do JFlex vamos utilizar a ferramenta Java Cup que já faz parte do pacote de desenvolvimento de JFlex que pode ser obtido nesse link - http://jflex.de/download.html.
Vocë pode obter mais detalhes do funcionamento do Java Cup em http://www2.cs.tum.edu/projects/cup/.
Ambas as ferramentas utilizam a linguagem de programação Java, vocë pode criar um projeto Java utilizando alguma IDE de desenvolvimento de sua preferencia, nos vamos apresentar apenas as partes relevantes na construção do analisador léxico e sintático omitindo detalhes do projeto.
Nessa etapa vamos utilizar o Maven para gerir as dependências, então para criar o projeto na IDE Eclipse faça File -> New > Other > Maven > Maven Project, escolha um nome de sua preferência e crie o projeto. Para essa etapa não é necessário baixar as bibliotecas manualmente ou configurar variáveis de ambiente.
No arquivo pom.xml acrescente as depedências do JFlex e Java CUP conforme abaixo:
<dependencies>
<!-- https://mvnrepository.com/artifact/de.jflex/jflex -->
<dependency>
<groupId>de.jflex</groupId>
<artifactId>jflex</artifactId>
<version>1.8.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.github.vbmacher/java-cup -->
<dependency>
<groupId>com.github.vbmacher</groupId>
<artifactId>java-cup</artifactId>
<version>11b</version>
</dependency>
</dependencies>
A construção de uma linguagem de programação deve iniciar pela definição léxica, abaixo é apresentado um fragmento de código escrito na linguagem que vamos construir que vai se chamarSextaFase.
program <{
@age INT:
@name STR:
&imprmir(^idade; ^nome) [
if TT [
$idade -> ^idade:
$nome -> ^nome:
]
if FF [
$nome -> ^nome:
]
]
%imprimir(~sdfsd~; 12; 12):
}>
Salvar esse código em um arquivo do seu projeto chamado Program.pg.
As seguintes convenções serão utilizadas na linguagem SextaFase:
- A palavra reservada
programdeve identificar o inicio do programa; - O bloco de inicio de fim do programa deve ser identificado através dos sinais
<{e}>. - O sinal de
:determina o termino de uma declaração; - Variáveis devem ser declaradas com o sinal
@, seguido do nome formado por um conjunto de letras e seu respectivo tipo:INTouSTR; - A declaração de funções deve ser precedida pelo sinal
&seguido por um conjunto de letras que formam o nome; - Os parâmetros das funções devem ser identificados pelo sinal
^seguido por um conjunto de letras; - As constantes verdadeiro e falso são identificados respectivamente por
TTeFF; - Os bloco de inicio e fim de uma instrução é identificado por
[e ']'; - Operações de atribuição são identificadas pelo símbolos
->; - A strings devem estar entre o sinal de
~; - As variáveis deve ser usadas colocando o sinal
$na frente do nome; - As funções são chamadas colocando o sinal
%na frente do nome; - Nas funções os parâmetros são separados por
;tando na declaração como na chamada;
Agora vamos criar o arquivo de especificação léxica. Dentro do projeto crie um arquivo chamado Lexer.lex com o seguinte conteúdo.
import java_cup.runtime.Symbol;
%%
%cup
%public
%class Lexer
%line
%column
DIGIT = [0-9]
LETTER = [a-zA-Z_]
COMMENT = \|\|.*\n
STRING = \~{LETTER}+\~
INTEGER = {DIGIT}+
VARIABLE = @{LETTER}+
ASSIGNMENT = \${LETTER}+
FUNCTION = &{LETTER}+
FUNCTION_PARAMS = \^{LETTER}+
CALL_FUNCTION = %{LETTER}+
IGNORE = [\n|\s|\t\r]
%%
<YYINITIAL> {
"program" {return new Symbol(Sym.PROGRAM); }
"if" {return new Symbol(Sym.IF); }
"<{" {return new Symbol(Sym.BEGIN); }
"}>" {return new Symbol(Sym.END); }
"INT" {return new Symbol(Sym.INTEGER_TYPE); }
"STR" {return new Symbol(Sym.INTEGER_TYPE); }
":" {return new Symbol(Sym.COLON); }
"(" {return new Symbol(Sym.LEFT_PARAMETER); }
")" {return new Symbol(Sym.RIGHT_PARAMETER); }
"[" {return new Symbol(Sym.LEFT_BRACKETS); }
"]" {return new Symbol(Sym.RIGHT_BRACKETS); }
";" {return new Symbol(Sym.SEMICOLON); }
"TT" {return new Symbol(Sym.TT); }
"FF" {return new Symbol(Sym.FF); }
"->" {return new Symbol(Sym.SYMBOL_ASSIGNMENT); }
{CALL_FUNCTION} {return new Symbol(Sym.CALL_FUNCTION); }
{ASSIGNMENT} {return new Symbol(Sym.ASSIGNMENT); }
{STRING} {return new Symbol(Sym.STRING); }
{INTEGER} {return new Symbol(Sym.INTEGER); }
{FUNCTION} {return new Symbol(Sym.FUNCTION); }
{FUNCTION_PARAMS} {return new Symbol(Sym.FUNCTION_PARAMS); }
{VARIABLE} {return new Symbol(Sym.VARIABLE); }
{IGNORE} {}
{COMMENT} {}
}
<<EOF>> { return new Symbol( Sym.EOF ); }
[^] { throw new Error("Illegal character: "+yytext()+" at line "+(yyline+1)+", column "+(yycolumn+1) ); }
Para que o analisador léxico desenvolvido com o JFlex funcione corretamente em conjunto com o analisador sintático Java Cup as seguintes instruções devem ser incluídas no arquivo lex.
%cup– indica que o analisador léxico será integrado ao Java Cup;%type java_cup.runtime.Symbol– especifica o tipo de retorno dos tokens quando identificados.return new Symbol(sym.INICIO)- Cada token identificado deve retornar uma instancia da classe Symbol que representa uma constante numérica. Essa constante é gerada automaticamente pelo Java Cup.
A próxima etapa é definir a gramática da linguagem de programação, nós vamos utilizar Gramática Livres de Contexto.
Abaixo um exemplo de uma gramática que pode ser utilizada para montar uma frase.
G = ({SENTENÇA, SN, SV, ARTIGO, VERBO, SUBSTANTIVO, COMPLEMENTO}, {aluno, o, estudou, compiladores} , P, SENTENÇA)
P {
SENTENÇA → SN SV
SN → ARTIGO SUBSTANTIVO
SV → VERBO COMPLEMENTO
COMPLEMENTO → ARTIGO SUBSTANTIVO | SUBSTANTIVO
ARTIGO → o
SUBSTANTIVO → aluno | compiladores
VERBO → estudou
}
Com as regras de produção acima é possível validar a seguinte frase: o aluno estudou compiladores.
Vamos criar um arquivo com as especificações sintáticas, esse arquivo deve ser chamado de Parser.cup e deve ter o seguinte conteúdo.
<nome do pacote>
import java_cup.runtime.*;
import java.util.*;
import java.io.*;
parser code {:
public void report_error(String message, Object info) {
System.out.println("Warning - " + message);
}
public void report_fatal_error(String message, Object info) {
System.out.println("Error - " + message);
System.exit(-1);
}
:};
terminal PROGRAM, BEGIN, END, VARIABLE, COLON, INTEGER_TYPE, STRING_TYPE, CALL_FUNCTION;
terminal RIGHT_PARAMETER, LEFT_PARAMETER, INTEGER, STRING, SEMICOLON, FUNCTION;
terminal FUNCTION_PARAMS, LEFT_BRACKETS, RIGHT_BRACKETS, TT, FF, IF, ASSIGNMENT;
terminal SYMBOL_ASSIGNMENT;
non terminal program, statements, statement, statement_function;
non terminal decl_variable, decl_call_function, decl_call_params, decl_params, decl_function, decl_if;
non terminal decl_boolean,decl_assignments, decl_assignment;
non terminal params_type, data_types;
start with program;
program ::= PROGRAM BEGIN statements END;
statements ::= statements statement | statement ;
statement ::= decl_variable | decl_call_function | decl_function;
decl_function ::= FUNCTION LEFT_PARAMETER decl_params RIGHT_PARAMETER LEFT_BRACKETS statement_function RIGHT_BRACKETS;
decl_params ::= decl_params SEMICOLON FUNCTION_PARAMS | FUNCTION_PARAMS | ;
statement_function ::= statement_function decl_if | decl_if;
decl_if ::= IF decl_boolean LEFT_BRACKETS decl_assignments RIGHT_BRACKETS;
decl_assignments ::= decl_assignments decl_assignment | decl_assignment ;
decl_assignment ::= ASSIGNMENT SYMBOL_ASSIGNMENT FUNCTION_PARAMS COLON;
decl_boolean ::= TT | FF;
decl_call_function ::= CALL_FUNCTION LEFT_PARAMETER decl_call_params RIGHT_PARAMETER COLON;
decl_call_params ::= decl_call_params SEMICOLON params_type | params_type | ;
params_type ::= INTEGER | STRING;
decl_variable ::= VARIABLE data_types COLON;
data_types ::= INTEGER_TYPE | STRING_TYPE;
Caso tenha sido criado um pacote no seu projeto Java, você deve substituir no arquivo
Parser.cupa tag<nome do pacote>pelo nome do pacote ou remove-la caso não esteja usando um pacote.
Esse arquivo contém as especificações sintáticas, que nada mais é do que a gramática da linguagem de programação. Da mesma forma que o analisador léxico gerado pelo Jflex, o analisador sintático também irá gerar código Java para validar a sintaxe da linguagem de programação.
Agora precisamos gerar o analisador léxico e o analisador sintático. Vamos criar três classes para auxiliar esse processo.
Crie uma classe chamada Generate conforme abaixo:
package src.sintatico;
import java.nio.file.Paths;
public class Generate {
private final static String SUB_PATH = "/src/main/java/src/sintatico/";
public static String[] getPath(String filename) {
String rootPath = Paths.get("").toAbsolutePath().toString();
String file[] = {rootPath+SUB_PATH + filename};
return file;
}
}
Observe o nome do pacote e ajuste conforme o que você estiver usando. Altere o atributo
subPathconforme o caminho de seu projeto.
Crie uma classe chamada GenerateParser e defina o seu método main conforme abaixo:
package src.sintatico;
import java.io.IOException;
import java_cup.internal_error;
public class GenerateParser {
public static void main(String[] args) throws internal_error, IOException, Exception {
String file[] = Generate.getPath("Parser.cup");
java_cup.Main.main(file);
}
}
Observe o nome do pacote e ajuste conforme o que você estiver usando.
Crie uma classe chamada GenerateLexer e defina o seu método main conforme abaixo:
package src.sintatico;
public class GenerateLexer {
public static void main(String[] args) {
String file[] = Generate.getPath("Lexer.lex");
jflex.Main.main(file);
}
}
Novamente observe o nome do pacote e ajuste conforme o que você estiver usando.
Execute as duas classes (GenerateLexer e GenerateParser) e atualize o projeto. Com isso foram gerados os arquivos de código Java Lexer.java, Parser.java e Sym.java. Esses arquivos vão fazer parte do compilador.
Para finalizar o projeto da linguagem de programação vamos criar uma classe que vai executar o compilador.
import java.io.FileReader;
import java.nio.file.Paths;
public class Main {
public static void main(String[] args) {
String rootPath = Paths.get("").toAbsolutePath().toString();
String subPath = "/src/";
String sourcecode = rootPath + subPath + "Program.pg";
try {
Parser p = new Parser(new Lexer(new FileReader(sourcecode)));
Object result = p.parse().value;
System.out.println("Compilacao concluida com sucesso...");
} catch (Exception e) {
e.printStackTrace();
}
}
}
Você pode alterar o nome da classe Java para outro qualquer, nesse exemplo nos estamos utilizando o nome
Main.
Essa classe vai executar o compilador da linguagem. Teste, provoque erros sintáticos e verifique a saída no console.
Código completo em repositórios de terceiros: https://github.com/RomeuRocha/analisador-lexico-e-sintatico
Criando Gramáticas Livres de Contexto com o JFlap
O JFLAP, Java Formal Languages & Automata Package, é uma ferramenta que utiliza recursos visuais para demonstrar conceitos básicos de Linguagens Formais e Autômatos Finitos.
Com o JFLAP é possível representar diversas variações de autômatos finitos, máquinas de Turing, expressões regulares, escrever e montar árvores de derivação de gramáticas livres de contexto entre outros assuntos relacionados ao estuado de Linguagens Formais e Autômatos Finitos.
Para mais detalhes dos recursos e de como usar o JFALP acesse o tutorial oficial disponível em http://www.jflap.org/tutorial/.
O JFLAP é um projeto escrito em Java, portanto você precisar ter o Java instalado para executar esse aplicativo.
A ultima versão dispensável o JFLAP é a 8, nos exemplos abaixo vamos utilizar essa versão.
Neste tópico vamos abordar como podemos utilizar o JFLAP para construir gramáticas e verificar a arvore de derivação gerada por determinada gramatica. Nós podemos verificar se a gramática esta de acordo com uma determinada sentença.
Ao abrir o JFLAP a seguinte tela é exibida.

Observe que temos um menu com varias opções, oque nos interessa nesse momento é o menu Grammar. Clicando nessa opção, a seguinte tela sera averta, esse vai ser nosso ambiente de trabalho.
Data a seguinte gramatica `G = ({S}, {a, b}, P, S), inclua as seguintes regras de produção no JFLAP.
S → aSa
S → bSb
S → λ
Veja como ficou o resultado dessa gramatica no JFLAP.
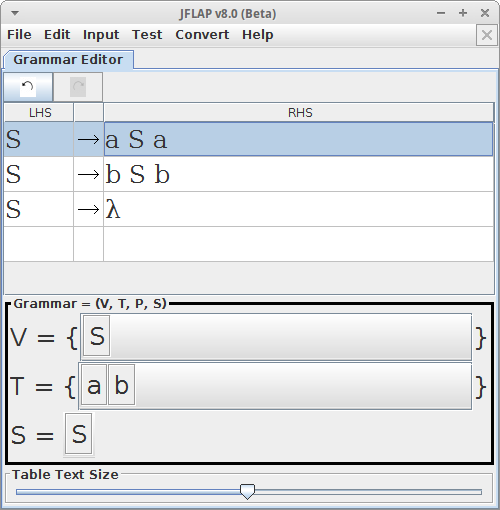
Nosso objetivo e verificar se as sentenças aabbaa e aabb são validas.
Acesse o menu Input -> Brute Force Parser, a seguinte tela ira abrir.
Com ela nos podemos realizar os testes e verificar a validade de uma sentença.
No campo Input digite a seguinte sentença aabb, clique no botão Set depois clique no botão Complet. Observe que uma mensagem aparece informado se a sentença é invalida ou invalida.
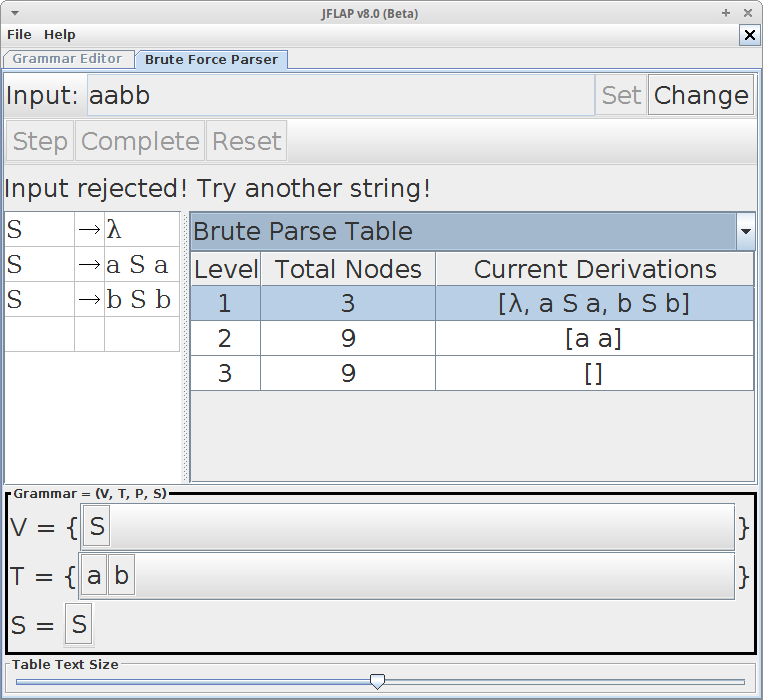
Observe que a sentença aabb não é valida para a gramatica desse exemplo.
Clique no botão Change e inclua a seguinte sentença aabbaa. Novamente clique no botão Set depois clique no botão Complet. Como essa sentença é valida o resultado foi o seguinte:
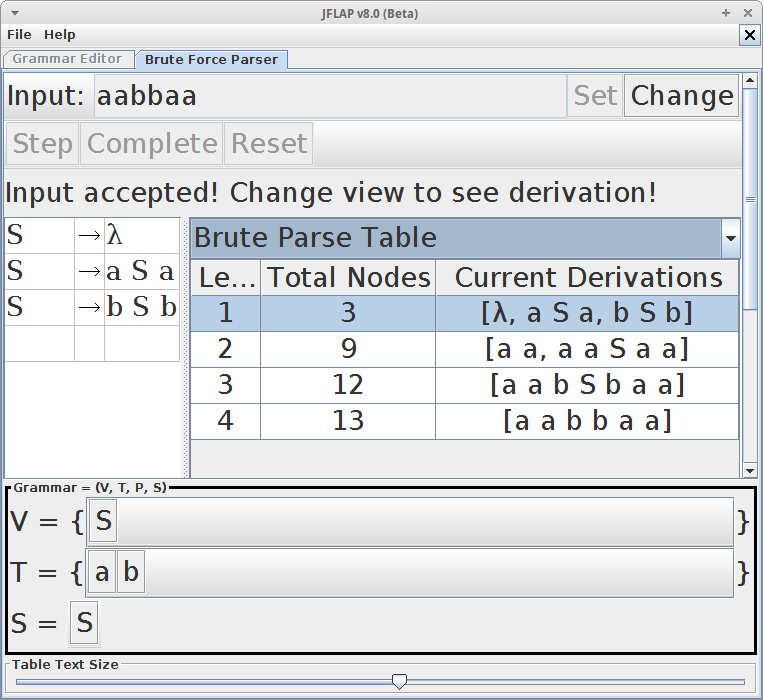
Um recurso muito interessante do JFLAP é o Derivation View que mostra a árvore de derivação de determinada sentença.
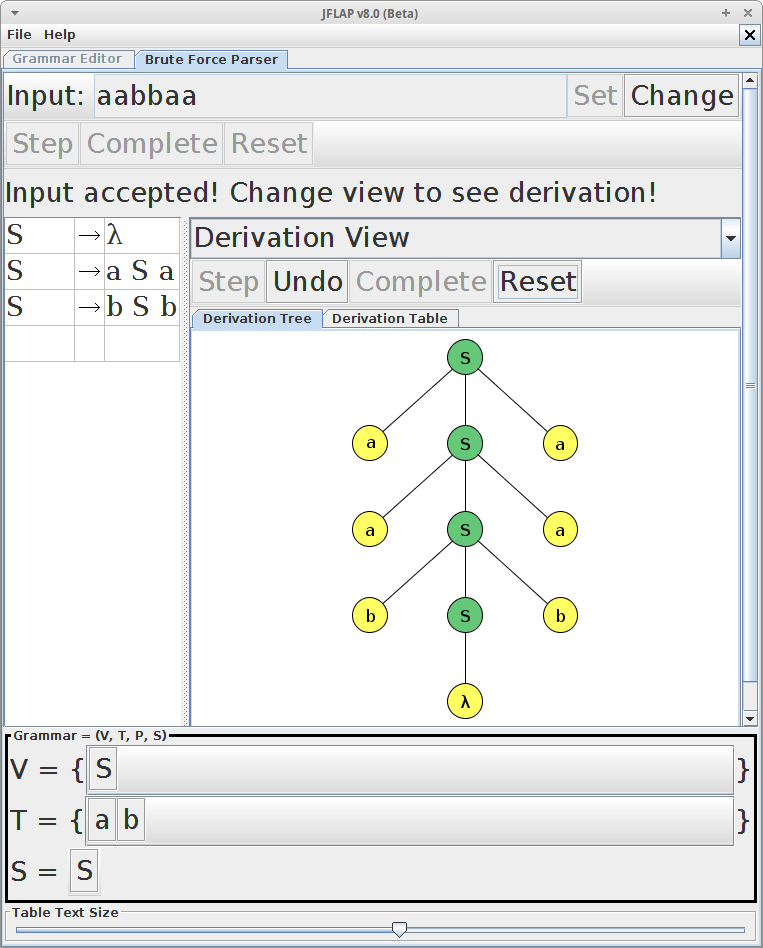
Observe que você pode utilizar o botoes Step, Undo, Reset e Complete para acompanhar o resultado da derivação da gramatica.
Nas etapas seguintes nos vamos utilizar vários exemplos de gramaticas em sequencia, para melhor entender esse conceito. Você pode fazer os testes das gramaticas no JFLAP, verificar o resultado de cada uma, e acompanhar a derivação.
Exemplo 01 - Linguagem formado por parenteses
Especificação das regras de produção:
S → SS
S → (S)
S → ()
S → λ
Sentenças:
()()- Válida()())- Inválida(())()- Válida
Exemplo 02 - Linguagem formado por parenteses e colchetes
Especificação das regras de produção:
S → SS
S → ()
S → (S)
S → []
S → [S]
S → λ
Sentenças:
()- Válida[]- Válida[()()]- Válida[([()])]- Válida[(])- Inválida[(([[]]))]- Válida
Exemplo 03 - Linguagem formada por pares de letras
Especificação das regras de produção:
S → aSb
S → ab
S → λ
Sentenças:
ab-Válidaabab- Inválidaaaabbb- Valida
Exemplo 04 - Linguagem formada por uma combinação de letras
Especificação das regras de produção:
S → SaSc
S → bSc
S → SaS
S → Sb
S → bS
S → λ
Sentenças:
ac- Válidaaac- Válidaaaac- Válidabbbbc- Válidaacd- Inválidaaaaaa- Válida
Exemplo 04 - Linguagem para operações de soma e multiplicação
Especificação das regras de produção:
S → x
S → xAx
S → (S)
A → +
A → *
Sentenças:
x+x- Válidax*x- Validax-x- Inválida+x- Inválida
O JFLAP é um software completo, você utilizar ele para validar gramáticas mais complexas.
Implementando um interpretador de operações matemáticas básicas
Nesse etapa nós vamos construir um interpretador de operações matemáticas básicas, o objetivo é demonstrar como podemos implementar um tradutor dirigido por sintaxe.
Vamos criar um analisador léxico com o JFlex e um analisador sintático com o Java Cup, ambas a bibliotecas pode ser baixadas nesse link - http://jflex.de/download.html.
A tradução dirigida por sintaxe tem como objetivo associar a execução de cada regra da gramatical uma ação semântica. Nesse projeto a ação semântica será avaliar a operação matemática e executar ela, interrompendo a operação e exibindo o seu resultado quando encontrar o simbolo de final de instrução.
Nós vamos utilizar um projeto Java, você pode utilizar qualquer IDE de desenvolvimento de sua preferencia. Vamos omitir os detalhes do projeto e focar somente nas partes relevantes para mostrar como um tradutor dirigido por sintaxe pode ser implementado.
Vamos começar definido as regras léxicas do nosso projeto, basicamente vamos avaliar as operações matemáticas básicas lidas de um arquivo, caso encontro um sinal de ; deve ser impresso o resultado da expressão.
Exemplo de sentenças validas:
(2 * 1) * 9; 1+ 3;
(1 + 3 + 5) * 8;
Crie um arquivo chamado calc.l e salve a sentenças nesse arquivo.
Crie um arquivo chamado Lexer.lex e coloque o seguinte conteúdo.
import java_cup.runtime.*;
%%
%class Lexer
%unicode
%cup
%line
%column
%{
private Symbol symbol(int type) {
return new Symbol(type, yyline, yycolumn);
}
private Symbol symbol(int type, Object value) {
return new Symbol(type, yyline, yycolumn, value);
}
%}
LineTerminator = \r|\n|\r\n
InputCharacter = [^\r\n]
WhiteSpace = {LineTerminator} | [ \t\f]
Digit = [0-9]
Number = {Digit} {Digit}*
Letter = [a-zA-Z]
%%
<YYINITIAL> {
{Number} { return symbol(Sym.NUMBER, new Integer(Integer.parseInt(yytext()))); }
"+" { return symbol(Sym.PLUS); }
"-" { return symbol(Sym.MINUS); }
"*" { return symbol(Sym.TIMES); }
"/" { return symbol(Sym.DIVIDED); }
"(" { return symbol(Sym.LPAREN); }
")" { return symbol(Sym.RPAREN); }
";" { return symbol(Sym.SEMI); }
{WhiteSpace} {}
}
<<EOF>> { return symbol( Sym.EOF ); }
[^] { throw new Error("Illegal character <" + yytext() + ">");}
Essas são a regras léxicas das expressões matemáticas.
Vamos utilizar Gramática Livres de Contexto para definir as regras sintáticas da nossa linguagem de programação.
Observe que cada regra sintática tem uma ação vinculada. Por exemplo expr:e SEMI {: System.out.println(">> " + e); :}, O código System.out.println(">> " + e); referente a expressão sintática expr:e SEMI será executa quando esse expressão for avaliada pelo compilador.
Veja em detalhes as outras ações semânticas vinculadas a avaliação das expressões sintáticas.
import java_cup.runtime.*;
parser code {:
public void report_error(String message, Object info) {
System.out.println("Warning - " + message);
}
public void report_fatal_error(String message, Object info) {
System.out.println("Error - " + message);
System.exit(-1);
}
:}
terminal SEMI, PLUS, MINUS, TIMES, DIVIDED, LPAREN, RPAREN;
terminal Integer NUMBER;
non terminal expr_list;
non terminal Integer expr;
precedence left PLUS, MINUS;
precedence left TIMES, DIVIDED;
expr_list ::= expr_list expr:e SEMI {: System.out.println(">> " + e); :}
| expr:e SEMI {: System.out.println(">> " + e); :}
;
expr ::= expr:e1 PLUS expr:e2 {: RESULT = e1+e2; :}
| expr:e1 MINUS expr:e2 {: RESULT = e1-e2; :}
| expr:e1 TIMES expr:e2 {: RESULT = e1*e2; :}
| expr:e1 DIVIDED expr:e2 {: RESULT = e1/e2; :}
| LPAREN expr:e RPAREN {: RESULT = e; :}
| NUMBER:n {: RESULT = n; :}
;
Crie um arquivo chamado Parser.cup e coloque conteúdo do analisador sintatico acima.
O código utilizada para executar o interpenetrador pode ser visto abaixo. Observe que ele abre o arquivo calc.l.
import java.io.FileNotFoundException;
import java.io.FileReader;
public class Main {
public static void main(String[] args) throws FileNotFoundException {
String fileName = "/home/johni/Projects/compiler-jflex-javacup-examples/OtherCalc/src/calc.l";
Parser parser = new Parser(new Lexer(new FileReader(fileName)));
try {
parser.parse();
}
catch (Exception e) {
System.out.println("Falha geral.");
}
}
}
O projeto do do interpretador esta pronto, agora no precisamos gerar o analisador léxico e o analisador sintático para concluir.
Acesse o programa de linha de comando e navegue até o diretório onde os arquivos lex e cup estão.
Por exemplo:
cd /home/johni/Projects/interpreter/calc/src/
Depois você deve localizar o diretório onde os arquivos jar do JFlex e Java Cup estão, e executar as seguintes linhas de código.
java -jar /home/johni/Projects/interpreter/vendor/jflex-1.6.1.jar Lexer.lex
java -jar /home/johni/Projects/interpreter/vendor/java-cup-11a.jar -parser Parser -symbols Sym Parser.cup
Você pode executar o projeto e ver que cada expressão matemática esta sendo avaliada no momento que ele é encontrada.
Referências
DELAMARO, M. E. Como construir um Compilador: utilizando ferramentas Java. São Paulo: Novatec, 2004.
FISCHER, Charles N.; CYTRON, Ron K.; LEBLANC, Richard J. Crafting a compiler. Boston: Addison-Wesley, 2010.
PRICE, Ana. TOSCANI, Simão. Implementação de Linguagens de Programação: Compiladores. 9ª. ed. Porto Alegre: Ed. Sagra Luzzato, 2001.
SANTOS, Pedro Reis; LANGLOIS, Thibault. Compiladores: Da Teoria à Prática. 1ª. ed. Lisboa: FCA, 2014.
SETHI, Ravi; ULLMAN, Jeffrey D.; LAM, Monica S. Compiladores: Princípios, Técnicas e Ferramentas. 2. ed. São Paulo: Pearson Addison Wesley, 2008.
TORCZON, Linda; KEITH, Cooper. Construindo Compiladores. 2ª. ed. Rio de Janeiro: Elsevier, 2014.
TUCKER, Allen B; NOONAN, Robert E. Linguagens de programação: princípios e paradigmas. 2. ed. São Paulo: McGraw-Hill, 2008. 599 p.
HOPCRAFT, Johu E; MOTWAM, Rajew. ULLMAN, Jeffrey D.; Introducao a teoria dos automatos, Lingagens e Computacao,